
23 TEIの使い方
Contents
This section discusses some technical topics concerning thedeployment of the TEI markup scheme documented elsewhere in theseGuidelines. In section 23.2 Personalization and Customization we discuss the scopeand variety of the TEI customization mechanisms, distinguishingbetween ‘clean’ modifications, which result in aschema that supports a subset of the distinctions made in the full TEIsystem, on the one hand, from ‘unclean’modifications, which result in a schema that does not have thisproperty. In 23.3 Conformance we define the notion of TEIConformance, distinguishing between documents which arealgorithmically TEI conformant ("TEI Conformable") from those which are intrinsicallyconformant ("TEI Conformant"); we also define the concept of a conformant TEIextension. Since the ODD markup description language defined inchapter 22 ドキュメンテーション向け要素 is fundamental to the way conformance andcustomization are handled in the TEI system, these two definitionalsections are followed by a section (23.4 Implementation of an ODD System) whichdescribes the intended behaviour of an ODD processor.
23.1 Obtaining the TEI SchemasTEI: Obtaining the TEI Schemas¶
As discussed in chapter 22 ドキュメンテーション向け要素, the modules making upthe TEI scheme are generated from a single set of XML sourcefiles. Schemas can be generated for TEI customizationsin each of XML DTD language, W3C schema language,and RELAX NG schema language. In the body of the Guidelines, onlythe latter form is presented, using the compact syntax.
The TEI schemas and Guidelines are widely available over theInternet and elsewhere. The canonical home for the TEI source, theschema fragments generated from it, and example modifications, is theTEI repository at http://tei.sf.net;versions are also available in other formats, along with copies of theGuidelines and related materials, from the TEI web site at http://www.tei-c.org.
23.2 Personalization and CustomizationTEI: Personalization and Customization¶
These Guidelines provide anencoding scheme suitable for encoding a very wide range of texts, andcapable of supporting a wide variety of applications. For this reason,the TEI scheme supports a variety of different approaches to solvingsimilar problems, and also defines a much richer set of elements thanis likely to be necessary in any given project. Furthermore, the TEIscheme may be extended in well-defined and documented ways for textsthat cannot be conveniently or appropriately encoded using what isprovided. For these reasons, it is almost impossible to use the TEIscheme without customizing or personalizing it in some way.
This chapter describes how the TEI encoding scheme may becustomized, and should be read in conjunction with chapter 22 ドキュメンテーション向け要素, which describes how a specific application of the TEIencoding scheme should be documented. The documentation systemdescribed in that chapter is, like the rest of the TEI scheme,independent of any particular schema or document type definitionlanguage.
Formally speaking, these Guidelines provide both syntactic rulesabout how elements and attributes may be used in valid documents andsemantic recommendations about what interpretation should be attachedto a given syntactic construct. In this sense, they provide both adocument type definition and a document typedeclaration. More exactly, we may distinguish between theTEI abstract model, which defines a set of relatedconcepts, and the TEI schema which defines a set ofsyntactic rules and constraints. Many (though not all) of the semanticrecommendations are provided solely as informal descriptive prose,though some of them are also enforced by means of such constructs asdatatypes (see 1.4.2 Datatype TEIのマクロ). Although the descriptionshave been written with care, there will inevitably be cases where theintention of the contributors has not been conveyed with sufficientclarity to prevent users of the Guidelines from‘extending’ them in the sense of attaching slightlyvariant semantics to them.
Beyond this unintentional semantic extension, some of the elementsdescribed can intentionally be used in a variety of ways; for example,the element note has an attribute type which cantake on arbitrary string values, depending on how it is used in adocument. A new type of ‘note’, therefore, requires no change inthe existing model. On the other hand, for some application, it may bedesired to constrain the possible values for the typeattribute to a small set of possibilities. A schema modified in thisway would no longer necessarily regard as valid the same set ofdocuments as the corresponding unmodified TEI schema, but would remainfaithful to the same conceptual model.
This section explains how the TEI scheme can be customized bysuppressing elements, modifying classes of elements, adding elements,and renaming elements. Documents which validate against anapplication of the TEI scheme which has been customized in this waymay or may not be considered ‘TEI conformant’, asfurther discussed in section 23.3 Conformance.
The TEI scheme is designed to support modification andcustomization in a documented way that can be validated by an XMLprocessor. This is achieved by writing a small TEI Conformantdocument, from which an appropriate processor can generate bothhuman-readable documentation, and a schema expressed in a languagesuch as RELAX NG or DTD. The mechanisms used to instantiate a TEIschema differ for different schema languages, and are therefore notdefined here. In XML DTDs, for example, extensive use is made ofparameter entities, while in RELAX NG schemas, extensive use is madeof patterns. In either case, the names of elements and, whereverpossible, their attributes and content models are definedindirectly. The syntax used to implement this indirection also varieswith the schema language used, but the underlying constructs in theTEI abstract model are given the same names.
- all the elements defined by the module (and described in the corresponding section of these Guidelines) are included in the schema;
- each such element is identified by the canonical name given it in these Guidelines;
- the content model of each such element is as defined by these Guidelines;
- the names, datatypes, and permitted values declared for eachattribute associated with each such element are as given in these Guidelines;
- the elements comprising element classes and the meaning of macrodeclarations expressed in terms of element classes is determined bythe particular combination of modules selected.
- particular elements may be suppressed, removing them from anyclasses in which they are members, and also from any generated schema;
- within certain limits, the name (generic identifier) associated with an element may be changed, without changing the semantic or syntacticproperties of the element;
- new elements may be added to an existing class, thus making themavailable in macros or content models defined in terms of those classes;
- additional attributes, or attribute values, may be specified for an individual element or for classes of elements;
- within certain limits, attributes, or attribute values, may also be removed either from an individual element or for classes of elements;
- the characteristics inherited by one class from another classmay be modified by modifying its class membership: all members of theclass then inherit the changed characteristics;
- the set of values legal for an attribute or attribute class maybe constrained or relaxed by supplying or modifying a value list, orby modifying its datatype.
The recommended way of implementing and documenting all such modifications is bymeans of the ODD system described in chapter 22 ドキュメンテーション向け要素; inthe remainder of this section we give specific examples to illustratehow that system may be applied. An ODD processor, such as the Romaapplication supported by the TEI, or any other comparable set ofstylesheets will use the declarations provided by an ODD to generateappropriate sets of declarations in a specific schema language such asRELAX NG or the XML DTD language. We do not discuss in detail here howthis should be done, since the details are schema language-specific;some background information about the methods used for XML DTD andRELAX NG schema generation is however provided in section 1.2 TEIスキーマの定義. Several example ODD files are also provided aspart of the standard TEI release: see further section 23.2.4 例 of Modification below.
23.2.1 Kinds of ModificationTEI: Kinds of Modification¶
- deletion of elements;
- renaming of elements;
- modification of content models;
- modification of attribute and attribute-value lists;
- modification of class membership;
- addition of new elements.
Each kind of modification changes the set of documents that will beconsidered valid according to the resulting schema. Any combination ofunchanged TEI modules may be thought of as defining a certain set ofdocuments. Each schema resulting from a modified combination of TEImodules will define a different set of documents. The set ofdocuments valid according to the unmodified schema may or may not beproperly contained in the set of documents considered to be validaccording to the modified schema. We use the term cleanmodification to describe a modification which regards as valida subset of the documents considered valid by the same combination ofTEI modules unmodified. Alternatively, the set of documents consideredvalid by the original schema might be disjoint from the set ofdocuments considered valid by the modified schema, with neither beingproperly contained by the other. Modifications that have this resultare called unclean modifications. Despite thisterminology, unclean modifications are not particularly deprecated,and their use may often be vital to the success of a project. Theconcept is introduced solely to distinguish the effects of differentkinds of modification.
Cleanliness can only be assessed with reference to elements in theTEI namespace.
23.2.1.1 Deletion of ElementsTEI: Deletion of Elements¶
The simplest way to modify the supplied modules is to suppress oneor more of the supplied elements. This is simply done by setting theattribute mode to delete on anelementSpec for the element concerned.
<moduleRef key="core"/>
<!-- other modules used by this schema -->
<elementSpec ident="note" module="core" mode="delete"/>
</schemaSpec>
In most cases, deletion is a clean modification, since mostelements are optional. Documents that are valid with respect to themodified schema are also valid according to the unmodified schema. Tosay this another way, the set of documents matching the new schema iscontained by the set of documents matching the original schema.
There are however some elements in the TEI scheme whichhave mandatory children; for example, the elementfileDesc must contain both a titleStmt and asourceDesc. A modification which deleted either of thesewould be unclean, because it would regard as valid documents that theunmodified schema would regard as invalid. Deleting one of the manyoptional children of fileDesc (editionStmt ornotesStmt for example) would not have this effect, and wouldbe a clean modification.
In general, whenever the element deleted by a modification ismandatory within the content model of some other (undeleted) element,the result is an unclean modification, and may also break the TEIabstract model (23.3.3 Conformance to the TEI Abstract Model). However, the parent of amandatory child can of course be removed safely if it is itselfoptional.
To determine whether or not an element is mandatory in a givencontext, the user must inspect the content model of the elementconcerned. In most cases, content models are expressed in terms ofmodel classes rather than elements; hence, removing an element willgenerally be a clean modification, since there will generally be othermembers of the class available. If a class is completely depopulatedby a modification, then the cleanliness of the modification willdepend upon whether or not the class reference is mandatory oroptional, in the same way as for an individual element.
23.2.1.2 Renaming of ElementsTEI: Renaming of Elements¶
Every element and other named markup construct in the TEI schemehas a canonical name, usually in the English language:this name is supplied as the value of the ident attributeon the elementSpec, attDef, classSpec, ormacroSpec used to define it. The element or attributedeclaration used within a schema generated from that specification mayhowever be different, thus permitting schemas to be written usingelements with generic identifiers from a different language, orotherwise modified. There may be many alternative identifiers for thesame markup construct, and an ODD processor may choose which of themto use for a given purpose. Each such alternative name is supplied bymeans of an altIdent element within the specification elementconcerned.
<altIdent>annotation</altIdent>
</elementSpec>
Renaming in this way is always a reversiblemodification. Although it is an inherently unclean modification(because the set of documents matched by the resulting schema isdisjoint with the set matched by its unmodified equivalent), theprocess of converting any document in which elements have been renamedinto an exactly equivalent document using canonical names iscompletely deterministic, requiring only access to the ODD in whichthe renaming has been specified. This assumes that the renamedelements used are not placed in the TEI namespace but either use anull namespace or some user-defined namespace, as further discussed in23.2.2 Modification and Namespaces; if this is not the case, care must be taken toavoid name collision between the new name and all existing TEInames. Furthermore, unclean modifications which do not specify anamespace are not conformant (see further 23.2 Personalization and Customization)
The TEI provides a systematic set of renamings into languages otherthan English. These all use a language-specific namespace.
23.2.1.3 Modification of Content ModelsTEI: Modification of Content Models¶
The content model for an element in the TEI scheme is defined bymeans of a content element within the elementSpecwhich specifies it. As shown elsewhere in these Guidelines, thecontent model is defined using RELAX NG syntax, whether theresulting schema is expressed in RELAX NG or in some other schemalanguage.
<rng:ref name="macro.phraseSeq"/>
</content>
<content>
<rng:text/>
</content>
</elementSpec>
This is a clean modification which does not change the meaning of aTEI element; there is therefore no need to assign the element to some other namespace thanthat of the TEI, though it may be considered good practice; see further 23.2.2 Modification and Namespacesbelow.
A change of this kind, which simplifies the possible content of anelement by reducing its model to one of its existing components, isalways clean, because the set of documents matched by the resultingschema is a subset of the set of documents which would have beenmatched by the unmodified schema.
Note that content models are generally defined (as far as possible)in terms of references to model classes, rather than to explicitelements. This means that the need to modify content models is greatlyreduced: if an element is deleted or modified, for example, then thedeletion or modification will be available for every content modelwhich references that element via its class, as well as those whichreference it explicitly. For this reason it is not (in general) goodpractice to replace class references by explicit element references,since this may have unintended side effects.
An unqualified reference to an element class within a content modelgenerates a content model which is equivalent to an alternation of allthe members of the class referenced. Thus, a content model whichrefers to the model class model.phrasewill generate a content model in which any one of the members of thatclass is equally acceptable. It is also possible to referencepredefined content model fragments based on classes, such as ‘anoptional repeatable alternation of all members of a class’, ‘a sequencecontaining no more than one of each member of the class’, etc. asdescribed further in 22.4.6 要素クラス.
Content model changes which are not simple restrictions on anexisting model should be undertaken with caution. The set of documentsmatching the schema which results from such changes is likely to bedisjoint with the set of documents matching the unmodified schema, andsuch changes are therefore regarded as unclean. When content modelsare changed or extended, care should be taken to respect the existingsemantics of the element concerned as stated in the Guidelines. Forexample, the element l is defined as containing a line ofverse. It would not therefore make sense to redefine its content modelso that it could also include members of the class model.pLike: such a modification althoughsyntactically feasible would not be regarded as TEI conformant becauseit breaks the TEI abstract model.
23.2.1.4 Modification of Attribute and AttributeValue リストTEI: Modification of Attribute and AttributeValue リスト¶
The attributes applicable to a given element may be specified intwo ways: they may be given explicitly, by means of anattList element within the correspondingelementSpec, or they may be inherited from an attributeclass, as specified in the classes element. To add a newattribute to an element, the schema builder should therefore firstcheck to see whether this attribute is already defined by someexisting attribute class. If it is, then the simplest method of addingit will be to make the element in question a member of that class, asfurther discussed below. If this is not possible, then a newattDef element must be added to the existing attListfor the element in question.
Whichever method is adopted, the modification capabilities are thesame as those available for elements. Attributes may be added ordeleted from the list, using the mode attribute onattdef in the same way as on elementSpec. The‘content’ of an attribute is defined by means of the datatype, valList, or valDesc elements within theattDef element. Any of these elements may be changed.
Suppose, for example, that we wish to add two attributes to theeg element (used to indicate examples in a text),type to characterize the example in some way, andsource to indicate where the example comes from. A quickglance through the Guidelines indicates that the attribute classatt.typed could be used to provide thetype attribute, but there is no comparable class which willprovide a source attribute. The existing egelement in fact has no local attributes defined for it at all: we willtherefore need to add not only an attDef element to definethe new attribute, but also an attList to hold it.
<attList>
<attDef
ident="source"
mode="add"
ns="http://www.example.org/ns/nonTEI">
<desc>specifies the source of an example by pointing to a
single bibliographic reference for it</desc>
<datatype maxOccurs="1">
<rng:ref name="data.pointer"/>
</datatype>
</attDef>
</attList>
</elementSpec>
The value supplied for the mode attribute on theattDef element is add; if this attribute alreadyexisted on the element we are modifying this should generate an error,since a specification cannot have more than one attribute of the samename. If the attribute is already present, we can replace the whole ofthe existing declaration by supplying replace as the valuefor mode; alternatively, we can change some parts of anexisting declaration only by supplying just the new parts, and settingchange as the value for mode.
Because the new attribute is not defined by the TEI,we must specify a namespace for it on the attDef; see further 23.2.2 Modification and Namespaces.
As noted above, adding the new type attribute involveschanging this element's class membership; we therefore discuss that inthe next section (23.2.1.3 Modification of Content Models).
The canonical name for the new attribute is source, andis supplied on the ident attribute of the attDefelement. In this simple example, we supply only a description anddatatype for the new attribute; the former is given by thedesc element, and the latter by the datatypeelement. (There are of course many other pieces of information whichcould be supplied, as documented in 22 ドキュメンテーション向け要素). The contentof the datatype element, like that of the contentelement, uses patterns from the RELAX NG namespace, in this case to selectone of the predefined TEI datatypes (1.4.2 Datatype TEIのマクロ).
<attList>
<attDef ident="source" ns="http://example.com/ns" mode="add">
<desc>specifies the source of an example by supplying one of three
predefined codes for it.</desc>
<datatype maxOccurs="1">
<rng:ref name="data.word"/>
</datatype>
<valList type="closed">
<valItem ident="A">
<desc>例 taken from the A-list</desc>
</valItem>
<valItem ident="B">
<desc>例 taken from the B-list</desc>
</valItem>
<valItem ident="C">
<desc>例 taken from the C-list</desc>
</valItem>
</valList>
</attDef>
</attList>
</elementSpec>
The same technique may be used to replace or extend thevalList supplied as part of any attribute in the TEIscheme.
Depending on the modification, the set of documents matched by aschema generated from an ODD modified in this way, may or may not be asubset of the set of documents matched by the unmodified schema. Assuch, it is difficult to tell in principle whether such modificationsare intrinsically unclean.
23.2.1.5 Class ModificationTEI: Class Modification¶
The concept of element classes wasintroduced in 1.3.2 モデルクラス; an understanding of it isfundamental to successful use of the TEI scheme. As noted there, wedistinguish model classes, the members of which allhave structural similarity, from attribute classes, themembers of which simply share a set of attributes.
The part of an element specification which determines its classmembership is an element called classes. All classes to whichthe element belongs must be specified within this, using amemberOf element for each.
ident="eg"
module="tagdocs"
mode="change"
ns="http://example.com/ns">
<classes mode="change">
<memberOf key="att.typed"/>
</classes>
</elementSpec>
ident="term"
module="core"
mode="change"
ns="http://example.com/ns">
<classes mode="change">
<memberOf key="att.declaring" mode="delete"/>
</classes>
</elementSpec>
ident="term"
module="core"
mode="change"
ns="http://example.com/ns">
<classes>
<memberOf key="att.interpLike"/>
</classes>
</elementSpec>
If however the mode attribute is set tochange, the implication is that the memberships indicatedby its child memberOf elements are to be combined withthe existing memberships for the element.
<attList>
<attDef ident="rend" mode="delete"/>
</attList>
</classSpec>
The classes used in the TEI scheme are further discussed in chapter1 TEIの基礎構造. Note in particular that classes are themselvesclassified: the attributes inherited by a member of attribute class Amay come to it directly from that class, or from another class ofwhich A is itself a member. For example, the class att.global is itself a member of the classesatt.global.linking and att.global.analytic. By default, these twoclasses are predefined as empty. However, if (for example) the linking module is included in a schema, a numberof attributes (corresp, sameAs, etc) are definedas members of the att.global.linkingclass. All elements which are members of att.global will then inherit these new attributes(see further section 1.3.1 属性クラス). A new attribute maythus be added to the global class in two ways: either by adding it tothe attList defined within the class specification for att.global; or by defining a new attribute class,and changing the class membership of the att.global class to reference it.
Such global changes should be undertaken with caution: in generalremoving existing non-mandatory attributes from a class will always bea clean modification, in the same way as removing non-mandatoryelements. Adding a new attribute to a class however can be aclean modification only if the new attribute is labelled as belongingto some namespace other than the TEI.
The same mechanisms are available for modification of modelclasses. Care should be taken when modifying the model classmembership of existing elements since model class membership is whatdetermines the content model of most elements in the TEI scheme, and asmall change may have unintended consequences.
23.2.1.6 Addition of New ElementsTEI: Addition of New Elements¶
To add a completely new element into a schema involves providing acomplete element specification for it, the classes element ofwhich includes a reference to at least one TEI model class. Withoutsuch a reference, the new element will not be referenced by thecontent model of any other TEI element, and will therefore beinaccessible within a TEI document.
<classes>
<memberOf key="model.biblLike"/>
</classes>
<!-- other parts of the new declaration here -->
</elementSpec>
23.2.2 Modification and NamespacesTEI: Modification and Namespaces¶
All the elements defined in the TEI scheme are labelled asbelonging to a single namespace, maintained by the TEIand with the URI http://www.tei-c.org/ns/1.0.83 Only elementswhich are unmodified or which have undergone a clean modification mayuse this namespace. In a TEI-conformant document, it is assumed thatall attributes not explicitly labelled with a namespace (such as, forexample xml:id) also belong to the TEI namespace, and aredefined by the TEI.
This implies that any other modification (including a renaming orreversible modification) must either specify a different namespace orspecify no namespace at all. The ns attribute is providedon elements schemaSpec, elementSpec, andattDef for this purpose.
<attList>
<attDef ident="topic" mode="add" ns="http://www.example.org/ns/nonTEI">
<desc>indicates the topic of a TEI paragraph</desc>
<datatype>
<!-- ... -->
</datatype>
</attDef>
</attList>
</elementSpec>
xmlns:my="http://www.example.org/ns/nonTEI">
<!-- ... -->
<p n="12" my:topic="rabbits">Flopsy, Mopsy, Cottontail, and
Peter...</p>
</div>
Since topic is explicitly labelled as belonging tosomething other than the TEI namespace, we regard the modificationwhich introduced it as clean. A namespace-aware processor will regardthis document as valid according to the unmodified schema.84
Similar methods may be used if a modification (clean or unclean) ismade to the content model or some other aspect of an element, or if itdeclares a new element.
<moduleRef key="header"/>
<!-- ... -->
</schemaSpec>
In addition to the TEI canonical namespace mentioned above, the TEIalso defines namespaces for approved translations of the TEI schemeinto other languages. These may be used as appropriate to indicate that acustomization uses a standardized set of renamings. The namespace forsuch translations is the same as that for the canonical namespace,suffixed by the two character language identifier. A schema specification usingthe Chinesetranslation, for example, would use the namespace http://www.tei-c.org/ns/1.0/zh
23.2.3 Documenting the ModificationTEI: Documenting the Modification¶
The elements used to define a TEI customization(schemaSpec, moduleRef, elementSpec, etc.)will typically be used within a TEI document which supplies furtherinformation about the intended use of the new schema, the meaning andapplication of any new or modified elements within it, and so on. Thisdocument will typically conform to a TEI (or other) schema whichincludes the module described in chapter 22 ドキュメンテーション向け要素85
Where the customization to be documented simply consists in aselection of modules, perhaps with some deletion of unwanted elementsor attributes, the documentation need not specify anythingfurther. Even here however it may be considered worthwhile to replacesome of the semantic information provided by the unmodified TEIspecification. For example, the desc element of an unmodifiedTEI elementSpec may describe an element in terms more generalthan appropriate to a particular project, or the exemplumelements within it may not illustrate the project's actual intendedusage of the element, or the remarks element may containdiscussions of matters irrelevant to the project. These elements maytherefore be replaced or deleted within an elementSpec asnecessary.
Radical revision is also possible. It is feasible to produce amodification in which the teiHeader or text elementsare not required, or in which any other rule stated in these Guidelinesis either not enforced or not enforceable. In fact, the mechanism, ifused in an extreme way, permits replacement of all that the TEI has tosay about every component of its scheme. Such revisions would resultin documents that are not TEI conformant in even the broadest sense,and it is not intended that encoders use the mechanism in thisway. We discuss exactly what is meant by the concept of TEIconformance in the next section, 23.3 Conformance.
23.2.4 例 of Modification TEI: 例 of Modification ¶
- tei_bare
- The schema generated from this customization is the minimum needed for TEI Conformance. It provides only a handful of elements.
- tei_all
- The schema generated from this customization combines all available TEI modules, providing over 500 elements.
- tei_allPlus
- The schema generated from this customization combines all available TEI modules with three other non-TEI vocabularies, specifically MathML, SVG, and XInclude.
It is unlikely that any project would wish to use any of theseextremes unchanged. However, they form a useful starting point forcustomization, whether by removing modules from tei_all or tei_allPlus, or byreplacing elements deleted from tei_bare. They also demonstrate how anODD document may be constructed to provide a basic reference manual toaccompany schemas generated from it.
Shortly after publication of the first edition of these Guidelines,as a demonstration of how the TEI encoding scheme might be adopted tomeet 90% of the needs of 90% of the TEI user community, the TEIeditors produced a brief tutorial defining one specific‘clean’ modification of the TEI scheme, which theycalled TEI Lite. This tutorial and its associated DTD became verypopular and are still available from the TEI web site athttp://www.tei-c.org/Lite/. The tutorial andassociated schema specification is also included as one of the Exemplars provided with TEI P5.
The Exemplars provided with TEI P5 also include a customizationfile from which a schema for the validation of other customizationfiles may be generated. This ODD, called tei_odds, combines the fourbasic modules with the tagdocs, dictionaries, gaiji, linking, andfigures modules as well as including the (non-TEI) module defining theRELAX NG language. This enables schemas derived from this customizationto validate examples contained within them in a number of ways,further described within the document.
23.3 ConformanceTEI: Conformance¶
- interchange or integration of documents amongst different researchers or users;
- software specifications for TEI-aware processing tools;
- agreements for the deposit of texts in, and distribution of texts from, archives;
- specifying the form of documents to be produced by or for a given project.
In this section we explore several aspects of conformance, and inparticular attempt to define how the term TEI Conformantshould be used. The terminology defined here should be considerednormative: users and implementors of the TEI Guidelines should use thephrases ‘TEI Conformant’,‘TEI Conformable’, and‘TEI Extension’ only in the senses given and withthe usages described.
- is a well-formed XML document (23.3.1 Well-formedness criterion)
- can be validated against a TEI Schema, that is, aschema derived from the TEI Guidelines (23.3.2 Validation Constraint)
- conforms to the TEI Abstract Model (23.3.3 Conformance to the TEI Abstract Model)
- uses the TEI Namespace correctly (23.3.4 Use of the TEI Namespace)
- is documented by means of a TEI Conformant ODDfile (23.3.5 Documentation Constraint) which refers to theTEI Guidelines
A document is also said to be TEI Conformant if it is awell-formed XML document which can be transformed algorithmically andautomatically into a TEI Conformant document as defined above without loss ofinformation. The terms algorithmically conformant or TEIConformable may be used to distinguish documents exhibitingthese kinds of conformance from others.
A document is said to use a TEI Extension if it is awell-formed XML document which is valid against a TEI Schema whichcontains additional distinctions, representing concepts not present inthe TEI abstract model, and therefore not documented in theseGuidelines. Such a document cannot, in general, be algorithmicallyconformant since it cannot be automatically transformed without lossof information. However, since one of the goals of the TEI is tosupport extensions and modifications, it should not be assumed thatno TEI document can include extensions: an extension which isexpressed by means of the recommended mechanisms is also a TEIdocument provided that those parts of it which are not extensions areTEI Conformant, or Conformable.
A TEI Conformant (or Conformable) document is said to followTEI Recommended Practice if, wherever the Guidelinesprefer one encoding practice to another, the preferred practice isused.
23.3.1 Well-formedness criterionTEI: Well-formedness criterion¶
These Guidelines mandate the use of well-formed XML asrepresentation format. Documents must conform to the World Wide WebConsortium recommendation of the Extensible Markup Language(XML) 1.0 (Fourth Edition) or successor editions found at http://www.w3.org/TR/xml/. Other ways of representing theconcepts of the TEI abstract model are possible, and otherrepresentations may be considered appropriate for use in particularsituations (for example, for data capture, or project-internalprocessing). But such alternative representations are at best‘TEI Conformable’, and cannot be considered in anyway TEI Conformant.
Previous versions of these Guidelines used SGML as a representationformat. With release P5, the only representation format supportedby these Guidelines becomes valid XML; legacy documents in SGML formatshould therefore be converted using appropriate software.
A TEI Conformant document must use the TEI namespace, and thereforemust also include an XML-conformant namespace declaration, as definedbelow (23.3.4 Use of the TEI Namespace).
The use of XML greatly reduces the need to consider hardware orsoftware differences between processing environments when exchangingdata. No special packing or interchange format is required for an XMLdocument, beyond that defined by the W3C recommendations, and nospecial ‘interchange’ format is therefore proposedby these Guidelines. For discussion of encoding issues that may arisein the processing of special character sets or non-standard writingsystems, see further chapter vi 言語と文字集合.
In addition to the well-formedness criterion, the W3C defines thenotion of a valid document, as being a well-formeddocument which matches a specific set of rules or syntacticconstraints, defined by a schema. As noted above, TEIconformance implies that the schema used to determine validity of agiven document should be derived from the present Guidelines,preferably by means of an ODD which references and documents theschema fragments which the Guidelines define.
23.3.2 Validation ConstraintTEI: Validation Constraint¶
All TEI Conformant documents must validate againsta schema file that has been derived from the published TEIGuidelines, combined and documented in the manner described insection 23.2 Personalization and Customization. We call the formal output of this process aTEI Schema.
A TEI Schema may be expressed in any or all of the XML DTD language, W3C XML Schema, and RELAX NG (both compact and XML formats); the TEI does not mandate use of any particular schema language, only that this schema86 should have been generated from a TEI ODD file that references the TEI Guidelines. Some of what is syntactically possible using the ODD formalism cannot be represented by all schema languages; and there are some features of some schema languages which have no counterpart in ODD. No schema language fully captures all the constraints implied by conformance to the TEI abstract model. A document which is valid according to a TEI schema represented using one schema language may not be valid against the same schema expressed in other languages; in particular the DTD language does not support namespaces. Features which cannot be represented in all schema languages are documented in chapters 22 ドキュメンテーション向け要素 and 23.4 Implementation of an ODD System.
As noted in section 23.2 Personalization and Customization, many varieties of TEIschema are possible and not all of them are necessarily TEIConformant; derivation from an ODD is a necessary but not asufficient condition for this.
23.3.3 Conformance to the TEI Abstract ModelTEI: Conformance to the TEI Abstract Model¶
The TEI Abstract Model is the conceptual schemainstantiated by the TEI Guidelines. These Guidelines define, bothformally and informally, a set of abstract concepts such as‘paragraph’ or ‘heading’, and their structuralrelationships, for example stating that‘paragraph’s do not contain‘heading’s. These Guidelines also define classes ofelements, which have both semantic and structural properties incommon. Those semantic and structural properties are also a part ofthe TEI abstract model; the class membership of an existing TEIelement cannot therefore be changed without changing themodel. Elements can however be removed from a class by deletion, andnew non-TEI elements can be added to existing TEI classes.
23.3.3.1 Semantic ConstraintsTEI: Semantic Constraints¶
It is an important condition of TEI conformance that elementsdefined in the TEI Guidelines as having one specific meaning shouldnot be used with another. For example, the element l isdefined in the TEI Guidelines as containing a line of verse. A schemain which it is redefined to mean a typographic line, or an orderedqueue of objects of some kind, cannot therefore be TEI Conformant,whatever its other properties.
The semantics of elements defined in the TEI Guidelines areconveyed in a number of ways, ranging from formally verifiabledatatypes to informal descriptive prose. In addition, a mappingbetween TEI elements and concepts in other conceptual models may beprovided by the equiv element where this is available.
A schema which shares equivalent concepts to those of the TEIconceptual model may be mappable to the TEI Schema by means of such amechanism. For example, the concept of paragraph, expressed in the TEIscheme by the p element is probably the same concept as thatexpressed in the Docbook scheme by the para element. In thisrespect (though not in others) a Docbook-conformant document mighttherefore be considered to be TEI Conformable. Such areas of overlapfacilitate interoperability, because elements from one namespace maybe readily integrated with those from another, but do not affect thedefinition of conformance.
A document is said to conform to the TEI AbstractModel if features for which an encoding is proposed by the TEIGuidelines are encoded within it using the markup and other syntacticproperties specified by means of a valid TEIConformant schema. That is, the abstract definition andmarkup structurally correspond to that in the TEI Guidelines even ifthe names of elements and attributes might not. Although it may bepossible to transform a document following the TEI AbstractModel into a TEI Conformant document, it is notitself conformant.
23.3.3.2 Mandatory Components of a TEI DocumentTEI: Mandatory Components of a TEI Document¶
- a single teiHeader element followed by a single text element, in that order; or
- in the case of a corpus or collection, a single overall teiHeader element followed by a series of TEI elements each with its own teiHeader
- Title Statement
- This should include the title of the TEI document expressed using a titleStmt element.
- 出版・頒布など Statement
- This should include the place and date of publication or distribution of the TEI document, expressed using the publicationStmt element.
- Source Statement
- For a document derived from some previously existing document, this must include a bibliographic description of that source. For a document not so derived, this must include a brief statement that the document has no pre-existing source. In either case, this will be expressed using the sourceDesc element.
23.3.4 Use of the TEI NamespaceTEI: Use of the TEI Namespace¶
The Namespaces Recommendation of the W3C (Bray et al. (eds.) (2006)) provides a way for an XML document to combinemarkup from different vocabularies without risking name collision andconsequent processing difficulties. While the scope of the TEI islarge, there are many areas in which it makes no particularrecommendation, or where it recommends that other defined markupschemes should be adopted, such as graphics or mathematics. It is alsoconsidered desirable that users of other markup schemes should be ableto integrate documents using TEI markup with their own system. To meetthese objectives without compromising the reliability of its encoding,a TEI Conformant document is required to make appropriate use of theTEI namespace.
All elements in a TEI Schema which representsconcepts from the TEI abstract model belong to the TEI namespace,http://www.tei-c.org/ns/1.0, maintained bythe TEI along with additional namespaces for language variants. ATEI Conformant document is required to declare the namespace for allthe elements it contains whether these come from the TEI namespace orfrom other schemes.
A TEI Schema may be created which assigns TEI elements to someother namespace, or to no namespace at all. A document using such aschema must be regarded as a TEI extension and cannot be consideredTEI Conformant, though it may be TEI Conformable. A document whichplaces non-TEI elements or attributes within the TEI namespace cannotbe TEI Conformant; such practices are strongly deprecated asthey may lead to serious difficulties for processing orinterchange.
23.3.5 Documentation ConstraintTEI: Documentation Constraint¶
As noted in 23.3.2 Validation Constraint above, a TEI Schema can only begenerated from a TEI ODD, which also serves to document the semanticsof the elements defined by it. A TEI Conformant document shouldtherefore always be accompanied by (or refer to) a valid TEI ODDfile specifying which modules, elements, classes, etc. are inuse together with any modifications or renamings applied, and fromwhich a TEI Schema can be generated to validate the document. The TEIsupplies a number of predefined TEI Customization exemplar ODDfiles and the schemas already generated from them (see 23.2.4 例 of Modification ), but most projects will typically need tocustomize the TEI beyond what these examples provide. It is assumed,for example, that most projects will customize the TEI scheme byremoving those elements that are not needed for the texts they areencoding, and by providing further constraints on the attribute valuesand element content models the TEI provides. All such customizationsmust be specified by means of a valid TEI ODD file.
As different sorts of customization have different implications forthe interchange and interoperability of TEI documents, it cannot beassumed that every customization will necessarily result in a schemathat validates only TEI Conformant documents. The ODD language permitsmodifications which conflict with the TEI abstract model, even thoughobserving this model is a requirement for TEI Conformance. The ODDlanguage can in fact be used to describe many kinds of markup scheme,including schemes which have nothing to do with the TEI at all.
Equally, it is possible to construct a TEI Schema which isidentical to that derived from a given TEI ODD file without using theODD scheme. A schema can constructed simply bycombining the predefined schema language fragments corresponding withthe required set of TEI modules and other statements in the relevantschema language. The status of such a schema with respect to thetei_all schema cannot however bedetermined, in general; it may therefore be impossible to determinewhether such a schema represents a clean modification or anextension. This is one reason for making the presence of a TEI ODDfile a requirement for conformance.
23.3.6 Varieties of TEI ConformanceTEI: Varieties of TEI Conformance¶
- Is it a valid XML document, for which a TEI Schema exists? Ifnot, then the document cannot be considered TEI Conformant in anysense.
- Is the document accompanied by a TEI Conformant ODDspecification describing its markup scheme and intended semantics? Ifnot, then the document can only be considered TEI Conformant if itvalidates against a predefined TEI Schema and conforms to the TEIabstract model.
- Does the markup in the document correctly represent the TEIabstract model? Though difficult to assess, this is essential to TEIconformance.
- Does the document claim that all of its elements come fromsome namespace other than the TEI (or no namespace)? If so, thedocument cannot be TEI Conformant, though it may be TEI Conformable.
- If the document claims to use the TEI namespace, in part orwholly, do the elements associated with that namespace in fact belongto it? If not, the document cannot be TEI Conformant; if so, and ifall non-TEI elements and attributes are correctly associated withother namespaces, then the document may be TEI Conformant.
- Is the document valid according to a schema made by combiningall TEI modules as well as valid according to the schema derived fromits associated ODD specification? If so, the document is TEIConformant.
- Is the document valid according to the schema derived from itsassociated ODD specification, but not according to tei_all? If so, thedocument uses a TEI extension.
- Is it possible automatically to transform the document into adocument which is valid according to tei_all, usingonly information supplied in the accompanying ODD and without loss ofinformation? If so, the document is TEI Conformable.
| A | B | C | D | E | F | G | H | |
| Conforms to TEI abstract model | Y | N | Y | Y | ? | Y | N | ? |
| Valid ODD present | Y | Y | Y | Y | Y | Y | Y | N |
| Uses only non-TEI namespace(s) or none | N | N | N | N | Y | N | Y | N |
| Uses TEI and other namespaces correctly | Y | Y | N | Y | N | Y | N | Y |
| Document is valid as a subset of tei_all | Y | N | Y | N | N | Y | N | Y |
| Document can be converted automatically to a form which isvalid as a subset of tei_all | Y | N | Y | N | N | Y | N | ? |
We assume firstly that each sample document assessed here is awell-formed XML document, and that it is valid against some schema.
The document in column A is TEI Conformant. Its tagging follows theTEI Abstract Model, both as regards syntactic constraints (itsl elements appear within div elements and not thereverse) and semantic constraints (its l elements appear tocontain verse lines rather than typographic ones). It is acccompaniedby a valid ODD which documents exactly how it uses the TEI. All theTEI-defined elements and attributes in the document are placed in theTEI namespace. The schema against which it is valid is a‘clean’ subset of the tei_all schema.
The document in column B is not a TEI document. Although it isaccompanied by a valid TEI ODD, the resulting schema includes some‘unclean’ modifications, and represents someconcepts from the TEI Abstract Model using non-TEI elements; forexample, it re-defines the content model of p to permitdiv within it, and it includes an elementpageTrimming which appears to have the same meaning as theexisting TEI fw element. It uses the TEI namespace correctlyto identify the TEI elements it contains, but the ODD does not containenough information automatically to convert its non-TEI elements intoTEI equivalents.
The document in column C is TEI Conformable. It is almost the sameas the document in column A, except that the names of the elementsused are not those specified by the TEI namespace. Because the ODDaccompanying it contains an exact mapping for each element name (usingthe altIdent element) and there are no name conflicts, it ispossible to make an automatic conversion of this document.
The document in column D is a TEI Extension. It combines elementsfrom its own namespace with unmodified TEI elements in the TEInamespace. Its usage of TEI elements conforms to the TEI AbstractModel. Its ODD defines a new blort element which has no exactTEI equivalent, but which is assigned to an existing TEI class;consequently its schema is not a clean subset oftei_all. If the associated ODD provided a way ofmapping this element to an existing TEI element, then this would beTEI Conformable.
The document in column E is superficially similar to document D,but because it does not use any namespace declarations (or,equivalently, it assigns unmodified TEI elements to its ownnamespace), it may contain name collisions; there is no way of knowingwhether a p within it is the same as the TEI's p orhas some other meaning. The accompanying ODD file may be used toprovide the human reader with information about equivalently namedelements in the TEI namespace, and hence to determine whether thedocument is valid with respect to the TEI Abstract Model but this isnot an automatable process. In particular, cases of apparent conflict(for example use of an element p to represent a concept notin the TEI Abstract Model but in the Abstract Model of some othersystem, whose namespace has been removed as well) cannot be reliablyresolved. By our current definition therefore, this is not a TEIdocument.
The document in column F is TEI Conformable. The differencebetween it and that in column D is that the new element blortwhich is used in this document is a specialisation of an existing TEIelement, and the ODD in which it is defined specifies the mapping (amy:blort may be automatically converted to a tei:segtype="blort", for example). For this to work, however, theblort must observe the same syntactic constraints as theseg; if it does not, this would also be a case of TEIExtension.
The document in column G is not a TEI document. Its structure isfully documented by a valid TEI ODD, but it does not claim torepresent the TEI Abstract Model, does not use the TEI namespace, andis not intended to validate against any TEI schema.
The document in column H is very like that in column A, but itlacks an accompanying ODD. Instead, the schema used to validate it isproduced simply by combining TEI schema fragments in the same way asan ODD processor would, given the ODD. If the resulting schema is aclean subset of tei_all, such a document is indistinguishable from aTEI Conformant one, but there is no way of determining (withoutinspection) whether this is the case if any modification or extensionhas been applied. Its status is therefore, like that of Text E,impossible to determine.
23.4 Implementation of an ODD SystemTEI: Implementation of an ODD System¶
This chapter specifies how a processing system may take advantageof the markup specification elements documented in chapter 22 ドキュメンテーション向け要素 of these Guidelines in order to produceproject specific user documentation, schemas in one or more schema languages, and validation tools for other processors.
The specifications in this chapter are illustrative but notnormative. Its function is to further illustrate the intended scopeand application of the elements documented in chapter 22 ドキュメンテーション向け要素, since it is believed that these may have applicationbeyond the areas directly addressed by the TEI.
An ODD processing system has to accomplish two main tasks. A set ofselections, deletions, changes, and additions supplied by an ODDcustomization (as described in 23.2 Personalization and Customization) must first bemerged with the published TEI P5 ODD specifications. Next, theresulting unified ODD must be processed to produce the desired outputs.
An ODD processor is not required to do these two stages insequence, but that may well be the simplest approach; the ODDprocessing tools currently provided by the TEIコンソーシアム, which arealso used to process the source of these Guidelines, adopt this approach.
23.4.1 Making a Unified ODDTEI: Making a Unified ODD¶
An ODD customization must contain a single schemaSpecelement, which defines the schema to be constructed.
| ns | (namespace) specifies the default namespace (if any) applicable to components of the schema. |
| start | specifies entry points to the schema, i.e. which elements are allowed to be used as the root of documents conforming to it. |
| prefix | specifies a prefix which will be appended to all patterns relating to TEI elements. This allows for external schemas to be mixed in which have elements of the same names as the TEI. |
| targetLang | (target language) Where names for element or attribute are available in more than one language, specifies which language to use when creating the objects in a schema. |
| docLang | (documentation language) Where the descrition for an element, attribute, class or macro is available in more than one language, specifies which languages to use when creating documentation. |
- specifications
- elements from the class model.oddDecl (by default elementSpec,classSpec, moduleSpec, and macroSpec);these must have a mode attribute which determines how theywill be processed.87 If the value of mode isadd, then the object is simply copied to the output, but ifit is change, delete, or replace,then it will be looked at by other parts of the process.
- references to specifications
- specGrpRef elements refer to specGrp elementsthat occur elsewhere in this, or another, document. AspecGrp element, in turn, groups together a set of ODDspecifications (among other things, including furtherspecGrpRef elements). The use of specGrp andspecGrpRef permits the ODD markup to occur at the points indocumentation where they are discussed, rather than all insideschemaSpec. The target attribute of anyspecGrpRef should be followed, and the elementSpec,classSpec, and macroSpec, elements in thecorresponding specGrp should be processed as described in theprevious item; specGrpRef elements should be processed asdescribed here.
- references to TEIのモジュール
- moduleRef elements with key attributes refer to components of the TEI. The value of the key attribute matches the ident attribute of a TEI module. The key must be dereferenced by some means, such as reading an XML file with the TEI ODD specification (either from the local hard drive or off the web), or looking up the reference in an XML database (again, locally or remotely); whatever means is used, it should return a stream of XML containing the element, class, and macro specifications collected together in the specified module. These specification elements are then processed in the same way as ifthey had been supplied directly within the schemaSpec being processed.
- references to external modules
- a moduleRef element may also refer to a compatibleexternal module by means of its url attribute; the contentof such modules, which must be available in the RELAXNG XML syntax, arepassed directly and without modification to the output schema whenthat is created.
- if there is an object in the ODD customization with the same value for theident attribute, and a mode value ofdelete,then the object from the module is ignored;
- if there is an object in the ODD customization with the same value for theident attribute, and a mode value ofreplace,then the object from the module is ignored, and the onefrom the ODD customization is used in its place;
- if there is an object in the ODD customizationwith the same value for theident attribute, and a mode value ofchange,then the two objects must be merged, as described below;
- if there is an object in the ODD customizationwith the same value for theident attribute, and a mode value ofadd,then an error condition should be raised;
- otherwise, the object from the module is copied to the result.
- Some components may occur only once within the merged object(for example attributes, and altIdent, content, orclasses elements). If such a component is found in the ODDcustomization, it will be copied to the output; if it is not foundthere, but is present in the TEI ODD specification, then that willbe copied to the output.
- Some components are grouping objects (attList,valList, for example); these are always copied to the output,and their children are then processed following the rules given inthis list.
- Some components are ‘identifiable’: thismeans that they are members of the att.identified class from which they inherit theident attribute; examples include attDef andvalItem. A components of this type will be processedaccording to its mode attribute, following the rules givenin this list.
- Some components may occur multiple times, but are neithergrouped nor identifiable. 例 include the members of model.glossLike such as equiv,desc, gloss, the exemplum,remarks, listRef, datatype ordefaultVal elements. These should be copied from both the TEIODD specification and the ODD customization, and all occurrencesincluded in the output.
<classes>
<memberOf key="att.typed"/>
</classes>
<content>
<!--…-->
</content>
</elementSpec>
<classes>
<memberOf key="att.typed"/>
</classes>
<content>
<!--… -->
</content>
<attList>
<attDef ident="subtype" mode="delete"/>
</attList>
</elementSpec>
<desc>marks paragraphs in prose.</desc>
<!--…-->
</elementSpec>
<desc xml:lang="es">marca párrafos en prosa.</desc>
<!--…-->
</elementSpec>
Similar considerations apply to multiple example elements, thoughthese are less likely to cause problems in documentation. Note thatexisting examples can only be deleted by supplying a completely newelementSpec in replace mode, since theexemplum element is not identifiable.
<!--…-->
<content>
<rng:choice>
<rng:oneOrMore>
<rng:ref name="model.pLike"/>
</rng:oneOrMore>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.personPart"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</rng:choice>
</content>
<!--…-->
</elementSpec>
<!--…-->
<content>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.pLike"/>
<rng:ref name="model.global"/>
<rng:ref name="figure"/>
<rng:ref name="figDesc"/>
<rng:ref name="model.graphicLike"/>
<rng:ref name="model.headLike"/>
</rng:choice>
</rng:zeroOrMore>
</content>
<!--…-->
</elementSpec>
The result of the work carried out should be a newschemaSpec which contains a complete and internallyconsistent set of element, class, and macro specifications, possiblyalso including moduleRef elements with urlattributes identifying external modules.
23.4.2 Generating SchemasTEI: Generating Schemas¶
- all datatype and other macro specifications must be collectedtogether and declared at the start of the output schema;
- all classes must be declared in the right order (since someclasses reference others, the order is significant);
- all elements are declared;
- any moduleRef elements with a url attributeidentifying an external schema must be processed.
- A RELAX NG (XML) schema is generated by creating wrappers around the content models taken directly from the ODD specification;a version re-expressed in the RELAX NG compact syntax is generated usingJames Clark's trang application.
- A DTD schema is generated by converting the RELAX NGcontent models to DTD language, often simplifying it to allow for the less-sophisticated output language.
- A W3C Schema schema is created by generating a RELAX NG schemaand then using James Clark's trang application.
Other projects may decide to follow a different route, perhapsimplementing a direct ODD to W3C Schema translator.
Secondly, it is possible to create two rather different styles ofschema. On the one hand, the schema can try to maintain all theflexibility of ODD by using the facilities of the schema language forparameterization; on the other, it can remove all customizationfeatures and produce a flat result which is not suitable for furthermanipulation. The TEI project currently generates both styles of schema; thefirst as a set of schema fragments in DTD and RELAX NG languages,which can be included as modules in other schemas, and customizedfurther; the second as the output from a processor such as Roma, inwhich many of the parameterization features have been removed.
<!-- ... -->
<classes>
<memberOf key="model.frontPart.drama"/>
</classes>
<content>
<rng:group>
<rng:zeroOrMore>
<rng:choice>
<rng:ref name="model.divTop"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
<rng:oneOrMore>
<rng:group>
<rng:ref name="model.common"/>
</rng:group>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:oneOrMore>
<rng:zeroOrMore>
<rng:ref name="model.divBottom"/>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:zeroOrMore>
</rng:group>
</content>
<!-- ... -->
</elementSpec>
In the remainder of these chapter, the terms simpleschema and parameterized schema are used todistinguish the two schema types. An ODD processor is not required tosupport both, though the simple schema output is generallypreferable for most applications.
<!--…-->
<content>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
<rng:optional>
<rng:ref name="speaker"/>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</rng:optional>
</content>
<!--…-->
</elementSpec>
<!--…-->
<content>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="model.global"/>
</rng:zeroOrMore>
</content>
<!--…-->
</elementSpec>
Finally, an application will need to have some method ofassociating the schema with document instances that use it. The TEI does notmandate any particular method of doing this, since different schemalanguages and processors vary considerably in their requirements.
Finally, ODD processors may wish to build in support for some ofthe methods for associating a document instance with a schema. The TEIdoes not mandate any particular method, but does suggest that thosewhich are already part of XML (the DOCTYPE declaration for DTDs) andW3C Schema (the xsi:schemaLocation attribute) be supportedwhere possible.
Note that declaration of the xsi:schemaLocationattribute in a W3C Schema schema is not permitted. Therefore, if W3CSchemas are being generated by converting the RELAX NG schema (forexample, with trang), it may be necessary toperform that conversion prior to adding thexsi:schemaLocation declaration to the RELAX NG.
It is recognised that this is an unsatisfactory solution, but itpermits users to take advantage of the W3C Schema facility forindicating a schema, while still permitting documents to be validatedusing DTD and RELAX NG processors without any conflict.
23.4.3 Names and Documentation in Generated SchemasTEI: Names and Documentation in Generated Schemas¶
- If a RELAX NG pattern or DTD parameter entityis being created, its name is the value ofthe corresponding ident attribute, prefixed by the value of anyprefix attribute on schemaSpec. This allows forelements from an external schema to be mixed in without risk of nameclashes, since all TEI elements can be given a distinctive prefixsuch as tei_. Thus<schemaSpec ident="test" prefix="tei_">may generate a RELAX NG (compact syntax) pattern like this:
<elementSpec ident="sp">
<!--...-->
</elementSpec>
</schemaSpec>tei_sp = element sp { ... }References to these patterns (or, in DTDs, parameter entities) also need tobe prefixed with the same value. - If an element or attribute is being created, its default name isthe value of the ident attribute, but if there is analtIdent child, its content is used instead.
- Where appropriate, the documentation strings in glossand desc should be copied into the generated schema. If thereis only one occurrence of either of these elements, it should beused regardless, but if there are several, local processing rules willneed to be applied. For example, if there are several with differentvalues of xml:lang, a locale indication in the processingenvironment might be used to decide which to use. For example,<elementSpec module="core" ident="head">might generate a RELAX NG schema fragment like the following, if thelocale is determined to be Chinese:
<equiv/>
<gloss>heading</gloss>
<gloss xml:lang="es">encabezamiento</gloss>
<gloss xml:lang="zh-tw">標題</gloss>
<gloss xml:lang="ja">表題</gloss>
<!-- ... -->
</elementSpec>head = ## 標題 element head { head.content, head.attributes }
- when a pattern for an attribute class is created,it is named after the attribute class identifier (as above)suffixed by .attributes(e.g. att.editLike.attributes);
- when a pattern for an attribute is created,it is named after the attribute class identifer (as above)suffixed by .attribute. and then the identifierof the attribute (e.g. att.editLike.attribute.resp);
- when a parameterized schema is created, eachelement generates patterns for its attributes and its contentsseparately, suffixing respectively .attributesand .contents to the element name.
23.4.4 Making a RELAX NG SchemaTEI: Making a RELAX NG Schema¶
To create a RELAX NG schema, the processorprocesses every macroSpec,classSpec, and elementSpec in turn, creatinga RELAX NG pattern for each, using the naming conventions listedabove. The order of declaration is not important, and a processormay well sort them into alphabetical order of identifier.
A complete RELAX NG schema must have a start elementdefining which elements can occur as the root of a document. TheODD schemaSpec has an optional start attribute,containing one or more element names, which can be used to construct start.
23.4.4.1 TEIのマクロTEI: TEIのマクロ¶
<content>
<rng:zeroOrMore>
<rng:choice>
<rng:text/>
<rng:ref name="model.gLike"/>
<rng:ref name="model.phrase"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</content>
</macroSpec>
<rng:zeroOrMore>
<rng:choice>
<rng:text/>
<rng:ref name="model.gLike"/>
<rng:ref name="model.phrase"/>
<rng:ref name="model.global"/>
</rng:choice>
</rng:zeroOrMore>
</rng:define>
23.4.4.2 ClassesTEI: Classes¶
<!-- ... -->
</classSpec>
<rng:choice>
<rng:ref name="num"/>
<rng:ref name="measure"/>
<rng:ref name="measureGrp"/>
</rng:choice>
</rng:define>
<rng:ref name="num"/>
<rng:ref name="measure"/>
<rng:ref name="measureGrp"/>
</rng:define>
<rng:define name="model.measureLike_sequenceOptional">
<rng:optional>
<rng:ref name="num"/>
</rng:optional>
<rng:optional>
<rng:ref name="measure"/>
</rng:optional>
<rng:optional>
<rng:ref name="measureGrp"/>
</rng:optional>
</rng:define>
<rng:define
name="model.measureLike_sequenceOptionalRepeatable">
<rng:zeroOrMore>
<rng:ref name="num"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="measure"/>
</rng:zeroOrMore>
<rng:zeroOrMore>
<rng:ref name="measureGrp"/>
</rng:zeroOrMore>
</rng:define>
<rng:define name="model.measureLike_sequenceRepeatable">
<rng:oneOrMore>
<rng:ref name="num"/>
</rng:oneOrMore>
<rng:oneOrMore>
<rng:ref name="measure"/>
</rng:oneOrMore>
<rng:oneOrMore>
<rng:ref name="measureGrp"/>
</rng:oneOrMore>
</rng:define>
<attList>
<attDef ident="enjamb" usage="opt">
<equiv/>
<desc>indicates whether the end of a verse line is marked by enjambement.</desc>
<datatype>
<rng:ref name="data.enumerated"/>
</datatype>
<valList type="open">
<valItem ident="no">
<equiv/>
<desc>the line is end-stopped
</desc>
</valItem>
<valItem ident="yes">
<equiv/>
<desc>the line in question runs on into the next
</desc>
</valItem>
<valItem ident="weak">
<equiv/>
<desc>the line is weakly enjambed
</desc>
</valItem>
<valItem ident="strong">
<equiv/>
<desc>the line is strongly enjambed</desc>
</valItem>
</valList>
</attDef>
</attList>
</classSpec>
<rng:ref name="att.enjamb.attribute.enjamb"/>
<rng:empty/>
</rng:define>
<rng:define name="att.enjamb.attribute.enjamb">
<rng:optional>
<rng:attribute name="enjamb">
<rng:ref name="data.enumerated"/>
</rng:attribute>
</rng:optional>
</rng:define>
<defaultVal>yes</defaultVal>
<valList type="closed">
<valItem ident="yes">
<desc>the name component is spelled out in full.</desc>
</valItem>
<valItem ident="abb">
<gloss>abbreviated</gloss>
<desc>the name component is given in an abbreviated form.</desc>
</valItem>
<valItem ident="init">
<gloss>initial letter</gloss>
<desc>the name component is indicated only by one initial.</desc>
</valItem>
</valList>
</attDef>
<rng:optional>
<rng:attribute name="full" defaultValue="yes">
<rng:choice>
<rng:value>yes</rng:value>
<rng:value>abb</rng:value>
<rng:value>init</rng:value>
</rng:choice>
</rng:attribute>
</rng:optional>
</rng:define>
23.4.4.3 ElementsTEI: Elements¶
An elementSpec produces a RELAX NG specification in twoparts; firstly, it must generate a definepattern by which other elementscan refer to it, and then it must generate anelement with the content model and attributes. It may be convenient to make two separate patterns, onefor the element's attributes and one for its content model.
The content model is created simply by copying the body of thecontentelement; the attributes are processed in the same way as those fromattribute classes, described above.
23.4.5 Making a DTDTEI: Making a DTD¶
- declare all model classes which have a predeclarevalue of true
- declare all macros which have a predeclarevalue of true
- declare all other classes
- declare the modules (if DTD fragments are beingconstructed)
- declare any remaining macros
- declare the elements and their attributes
<desc>specifies the faith, religion, or belief set of a person.</desc>
<classes>
<memberOf key="model.persTraitLike"/>
<memberOf key="att.editLike"/>
<memberOf key="att.datable"/>
</classes>
<content>
<rng:ref name="macro.phraseSeq"/>
</content>
</elementSpec>
23.4.6 Generating DocumentationTEI: Generating Documentation¶
In Donald Knuth's literate programming terminology (Knuth (1992)),the previous sections have dealt with the tangle process;to generate documentation, we now turn to the weave process.
An ODD customization may consist largely of general documentationand examples, requiring no ODD-specific processing. It will normallyhowever also contain a schemaSpec element and possibly somespecGrp fragments.
The generated documentation may be of two forms. On the one hand,we may document the customization itself, that is, only those elements(etc.) which differ in their specification from that provided by theTEI reference documentation. Alternatively, we may generate referencedocumentation for the complete subset of the TEI which results fromapplying the customization. The TEI Roma tools take the latterapproach, and operate on the result of the first stage processingdescribed in 23.4.1 Making a Unified ODD.
Generating reference documentation for elementSpec, classSpec, and macroSpec elements is largelydependent on the design of the preferred output. Some applicationsmay, for example, want to turn all names of objects into hyperlinks,show lists of class members, or present lists of attributes as tables,lists, or inline prose. Another technique implemented in theseGuidelines is to show lists of potential ‘parents’for each element, by tracing which other elements have them aspossible members of their content models.
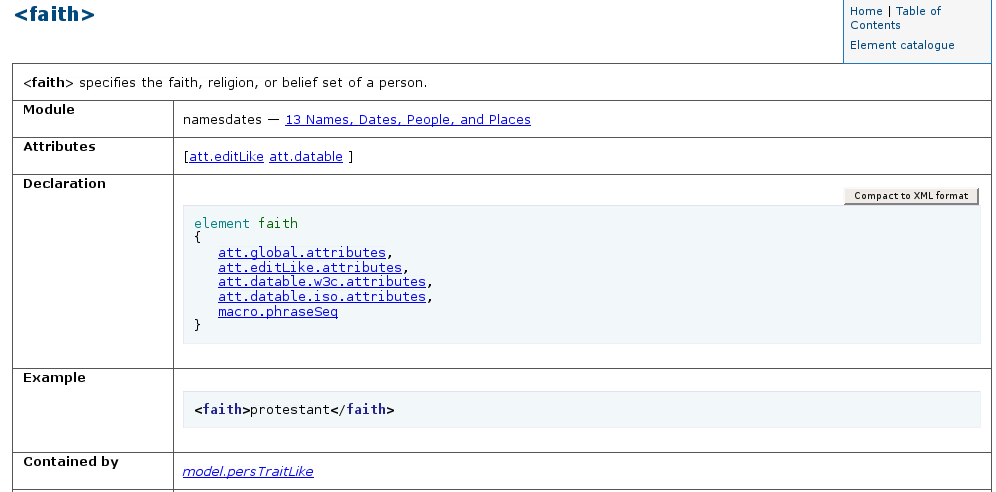
One model of display on a web page is shown in Figure Figure 6, Example reference documentation for faith,corresponding to the faith element shown in section23.4.5 Making a DTD.
23.4.7 Using TEI Parameterized Schema FragmentsTEI: Using TEI Parameterized Schema Fragments¶
The TEI parameterized DTD and RELAX NG fragments make use of parameterentities and patterns for several purposes. In this section wedescribe their interface for the user. In general we recommend use ofODD instead of this technique.
23.4.7.1 Selection of ModulesTEI: Selection of Modules¶
Special-purpose parameter entities are used to specify whichmodules are to be combined into a TEI DTD. They take the formTEI.xxxxx where xxxx is the name of the moduleas given in table Table 1 in 1.1 TEIのモジュール. For example, the parameter entity TEI.linking is used to define whether or not toinclude the module linking. All suchparameter entities are declared by default with the valueIGNORE: to select a module, therefore, the encoder declaresthe appropriate parameter entities with the value INCLUDE.
For XML DTD fragments, note that somemodules generate two DTD fragments: for example the analysis module generates fragments calledanalysis-decl and analysis. This is because the declarationsthey contain are needed at different points in the creation of an XMLDTD.
The RELAX NG schema fragments can be combined in a wrapper schemausing the standard mechanism of include in that language.
23.4.7.2 Inclusion and Exclusion of ElementsTEI: Inclusion and Exclusion of Elements¶
The TEI DTD fragments also use marked sections and parameter entityreferences to allow users to exclude the definitions of individualelements, in order either to make the elements illegal in a documentor to allow the element to be redefined. The parameter entities usedfor this purpose have exactly the same name as the generic identifierof the element concerned. The default definition for these parameterentities is INCLUDE but they may be changed toIGNORE in order to exclude the standard element andattribute definition list declarations from the DTD.
These parameter entities are defined immediately preceding theelement whose declarations they control; because their names arecompletely regular, they are not documented further.
23.4.7.3 Changing the Names of Generic IdentifiersTEI: Changing the Names of Generic Identifiers¶
These declarations are generated by an ODD processorwhen TEI DTD fragments are created.
23.4.7.4 Embedding Local Modifications(DTD only)TEI: Embedding Local Modifications(DTD only)¶
Any local modifications to a DTD (i.e. changes to a schema other than simpleinclusion or exclusion of modules) are made by declarations stored inone of two local extension files, one containing modifications to theTEI parameter entities, and the other new or changed declarations ofelements and their attributes. Entity declarations must be madewhich associate the names of these two files with the appropriateparameter entity so that the declarations they contain can be embeddedwithin the TEI DTD at an appropriate point.
- TEI.extensions.ent
- identifies a local file containingextensions to the TEI parameter entities
- TEI.extensions.dtd
- identifies a local file containingextensions to the TEI module
When an entity is declared more than once, the first declaration isbinding and the others are ignored. The local modifications toparameter entities should therefore be handled before the standardparameter entities themselves are declared in tei.dtd. The entity TEI.extensions.ent is referred to before any TEIdeclarations are handled, to allow the user's declarations to takepriority. If the user does not provide a TEI.extensions.ent entity, the entity will be expandedto the empty string.
For example the encoder might wish to add two phrase-level elementsit and bd, perhaps as synonyms for hirend='italics' and hi rend='bold'. As described inchapter 23.2 Personalization and Customization, this involves two distinct steps: one todefine the new elements, and the other to ensure that they are placedinto the TEI document structure at the right place.
Creating the new declarations is done in the same way foruser-defined elements as for any other; the same parameter entitiesneed to be defined so that they may be referenced by otherelements. The content models of these new elements may also referenceother parameter entities, which is why they need to be declared afterother declarations.
↑ Contents « 22 ドキュメンテーション向け要素 » 付録 A モデルクラス