
20 非階層構造
Contents
- « 19 グラフ,ネットワーク,木
- » 21 確信度・責任
- Home | 目次
文書の物理的な構造(例えば,巻,ページ,段,行など)と,修 辞的・言語的構造(例えば,章,段,文,幕,場など)の競合.
韻文テキストにある韻律構造(例えば,連や韻文行の配置など) や,修辞的・言語的構造(例えば,句,文,幕,場,科白など) の競合.
韻律的・修辞的・言語的構造と,実際の発話との競合. 例えば,引用された発話が,他の要素で分断されていたり(例え ば,'What', she asked, 'was that all about'),韻律・ 修辞言語学上の境界が異なっていたりする場合.
テキストや文書の異なる分析や記述の競合. 例えば,写本にある単語の描かれ方を,そのままに記録するマー クアップと,形態論や句点法に関心を持ちテキストをマークアッ プするものにある違い.
入れ子化されない情報は,XMLのスキームで符号化する際に,根本的 な問題を生むことになる. 現行では,テキスト中に現れる,または見いだされる情報を,形式的・ 機械的に妥当なものとして,簡単な形式で,所望する全ての属性をま とめることは出来ないことを,予め示しておくべきであろう. 非階層構造の情報を表示することは,各種の利点や欠点の,バラン スを取ることが必須の課題となる.
複数の形式を使い,当該情報を,冗長に符号化する(20.1 複数の符号化方法).
非階層構造の境界を,空要素で示す(20.2 空要素を使った境界).
論理構造では1つの入れ子化しない要素を,階層構造上適切に 入れ子化できる要素に分割する. 但し,これらの分割された要素は,階層構造の境界を越えて, 仮想的に再構成することができる(20.3 仮想要素を使った分 割・統合).
スタンドオフスタイル.これは,アノテーションを,XMLのタ グ中に示すのではなく,参照する手法で示すことである(20.4 スタンドオフスタイル).
Scorn not the sonnetである.
Essay on Psychiatristsの第4章から3番目の連(スタンザ)である.
- » 20.2 空要素を使った境界
- Home | 目次
20.1 複数の符号化方法TEI: 複数の符号化方法¶
同じ情報にある2つ(またはそれ以上)の競合する構造を解きほぐす,理 念上,一番簡単な方法は,それらを1つの視点毎に,2つ(またはそ れ以上)の視点の数だけ符号化する事である.
Scorn not the sonnetを「韻律」 の視点で符号化すれば,各韻文行を要素lを使い,以下 のように記録することが出来る.
<l>Mindless of its just honours; with this key</l>
<l>Shakespeare unlocked his heart; the melody</l>
<l>Of this small lute gave ease to Petrarch's wound.</l>
<s>Scorn not the sonnet;</s>
<s>critic, you have frowned, Mindless of its just honours;</s>
<s>with this key Shakespeare unlocked his heart;</s>
<s>the melody Of this small lute gave ease to Petrarch's wound.</s>
</p>
<l>Catholic woman of twenty-seven with five children</l>
<l>And a first-rate body—pointed her finger</l>
<l>at the back of one certain man and asked me,</l>
<l>"Is that guy a psychiatrist?" and by god he was! "Yes,"</l>
<l>She said, "He <emph>looks</emph> like a psychiatrist."</l>
<l>Grown quiet, I looked at his pink back, and thought.</l>
</lg>
<s>Catholic woman of twenty-seven with five children And a first-rate
body—pointed her finger at the back of one certain man and asked me,
"Is that guy a psychiatrist?" and by god he was!</s>
</p>
<p>
<s>"Yes," She said, "He <emph>looks</emph> like a psychiatrist."</s>
</p>
<p>
<s>Grown quiet, I looked at his pink back, and thought.</s>
</p>
body—pointed her finger at the back of one certain man and asked me,
<said>Is that guy a psychiatrist?</said> and by god he was!
<said>Yes,</said> She said, <said>He <emph>looks</emph> like a
psychiatrist.</said> Grown quiet, I looked at his pink back, and
thought.</ab>
この手法は,TEIに準拠している. この手法の利点は,それぞれの視点がデータ中に明示されているこ と,簡単に処理できることである. この手法の欠点は,同一テキスト内容の複数のコピーを管理する必 要があること(内容の一貫性をなくしやすい),別のファイルに記録 された場合,複数の視点の関連性を明示することが出来ないことが ある. 複数の視点で記録されたデータや,ある視点のデータから他の視点 のデータを含むファイルを処理する為にアクセスすることは,難し い. 78
20.2 空要素を使った境界TEI: Boundary Marking with Empty Elements¶
ひとつのXML文書中に非階層構造の情報を記録する,2つ目の方法 は,入れ子化しない部分の,開始点と終了点を作ることである. これにより,当該テキストの階層構造からは外れているテキストの 素性を,その開始点と終了点が処理されることになっても,当該文 書の妥当性を保つことが出来る. この手法の欠点は,XML要素ひとつで,入れ子化しない部分を示す ことは出来ず,結果として,XMLデータを処理することが難しくな ることである.
開始点と終了点を作るために使われる空要素は,「部分境界(segment-boundary)要素」 または「部分境界デリミタ」と呼ばれている. この手法は,さらにいくつかの手法に分けられる.
<s>
<lb n="1"/>Scorn not the sonnet;</s>; <s>critic, you have
frowned, <lb n="2"/>Mindless of its just honours;</s>
<s>with this key <lb n="3"/>Shakespeare unlocked his heart;</s>
<s>the melody <lb n="4"/>Of this small lute gave ease to Petrarch's
wound.</s>
</p>
これらの要素を使うことは,TEIに準拠している. 但し,各標石要素の意味は,決められていることに注意すべきであ る. 例えば,要素lb は,新しい(印刷)行の始まりを示す,という意味がある. 現代では,詩の多くは,印刷上と韻律上の行は対応しているが,要 素lbは,必ずしも,韻文行 を記録しているとは限らない. 韻文を符号化する,例えば,古英語の写本を記録する場合には,物 理的な行は,韻文行を表しているわけではなく,これらは対応して いない.
<anchor subtype="sentenceStart" type="delimiter"/> Scorn not the sonnet; <anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> critic, you have frowned,
</l>
<l>Mindless of its just honours; <anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> with this key</l>
<l>Shakespeare unlocked his heart; <anchor subtype="sentenceEnd" type="delimiter"/>
<anchor subtype="sentenceStart" type="delimiter"/> the melody</l>
<l>Of this small lute gave ease to Petrarch's wound. <anchor subtype="sentenceEnd" type="delimiter"/>
</l>
この手法は,TEIに準拠している.
<sentenceBoundaryStart xmlns="http://www.example.org/ns/nonTEI"/>Scorn not the sonnet;
<sentenceBoundaryEnd xmlns="http://www.example.org/ns/nonTEI"/>
<sentenceBoundaryStart xmlns="http://www.example.org/ns/nonTEI"/>critic, you have frowned,
</l>
<l>Mindless of its just honours; <sentenceBoundaryEnd xmlns="http://www.example.org/ns/nonTEI"/>
<sentenceBoundaryStart xmlns="http://www.example.org/ns/nonTEI"/>with this key</l>
<l>Shakespeare unlocked his heart; <sentenceBoundaryEnd xmlns="http://www.example.org/ns/nonTEI"/>
<sentenceBoundaryStart xmlns="http://www.example.org/ns/nonTEI"/>the melody</l>
<l>Of this small lute gave ease to Petrarch's wound. <sentenceBoundaryEnd xmlns="http://www.example.org/ns/nonTEI"/>
</l>
このような自前の要素を,TEIの要素や属性と,情報が失われるこ となく,置き換えることが出来れば,この手法はTEIに準拠したも のとなる(23.3 Conformance). この様な自前の要素が,TEIが規定する要素では捉えきれない情報 や区分を含んでいる場合には,この手法は,TEIを拡張したものと なる.
<l>
<s>Scorn not the sonnet;</s>
<s xmlns="http://www.example.org/ns/nonTEI" sID="s02"/>critic, you have frowned, </l>
<l>Mindless of its just honours; <s xmlns="http://www.example.org/ns/nonTEI" eID="s02"/>
<s xmlns="http://www.example.org/ns/nonTEI" sID="s03"/>with this key </l>
<l>Shakespeare unlocked his heart; <s xmlns="http://www.example.org/ns/nonTEI" eID="s03"/>
<s xmlns="http://www.example.org/ns/nonTEI" sID="s04"/>the melody </l>
<l>Of this small lute gave ease to Petrarch's wound. <s xmlns="http://www.example.org/ns/nonTEI" eID="s04"/>
</l>
</lg>
- 変更された要素が,別個のものとしてあり,その名前はTEI の名前空間には存在せず(23.3.4 Use of the TEI Namespace),また,変更された要素や属性は,情報を失 うことなく,既存のTEI構造,例えば,標石要素やアンカーに,規 則的に対応可能である場合,この手法はTEIに準拠したものと なる(23.3 Conformance).
- 変更された要素が,別個のものとしてあり,その名前はTEI の名前空間には存在しないが,既存のTEI要素には,規則的に は情報を失うことなく対応付けることが出来ないような情報を 含んでいる場合,この手法はTEIを拡張したものとなる(23.3 Conformance).
- 変更された要素や属性が,別個のものとして存在せず,その名 前がTEIの名前空間に存在している場合,この方法はTEIに準拠し ないものとなる(23.3.3 Conformance to the TEI Abstract Model).
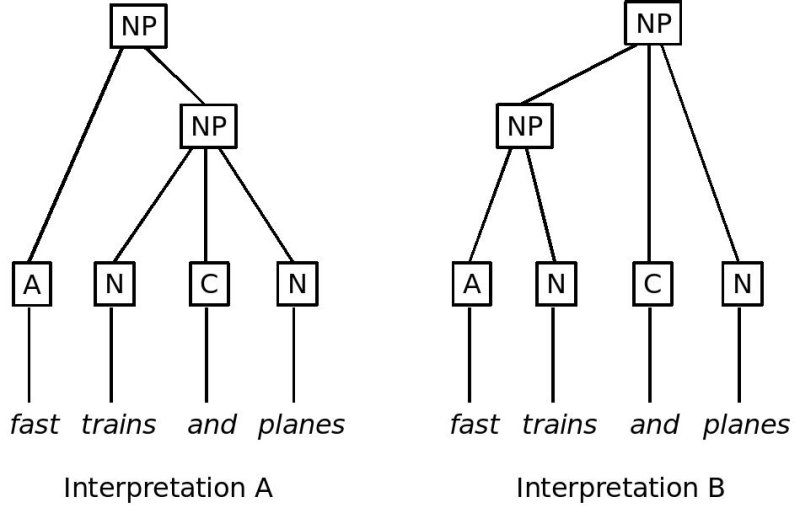
<anchor type="delimiter" subtype="NPstart" xml:id="NPInterpretationB"/>
<w function="A">Fast</w>
<anchor type="delimiter" subtype="NPstart" xml:id="NPInterpretationA"/>
<w function="N">trains</w>
<anchor type="delimiter" subtype="NPend" corresp="#NPInterpretationB"/>
<w function="C">and</w>
<w function="N">planes</w>
<anchor type="delimiter" subtype="NPend" corresp="#NPInterpretationA"/>
</phr>
この例では,1つ目の解釈として,「fast」が名詞句「trains and planes」を修飾していとし ている. 名詞句「trains and planes」は, 要素anchorの属性xml:idに属性値NPInterpretationAを持たせて,その 開始点が示され,要素anchorの属性correspに同じ属性値を持たせて,その終了 点が示されている. 2つ目の解釈では,「fast」は 「trains」と共に名詞句を形成 し,要素anchorの属性xml:idに属性値NPInterpretationBを与えて,その開始 点が示され,要素anchorの属性correspに同じ属性値を与えて,その終了点が 示されている.
このような利点がある一方で,部分境界を示すデリミタを使うこと には,処理を面倒にするという欠点がある. 分析のための要素(例えば,詩における行や,先の例にある句など) は,文書の木構造にあるノードを使い統一的に示されることがない. 従って,これらはソフトウェアにより,その都度,再構築される必 要がある. これは,大変に難しいことで,間違いを起こしやすい.
符号化する人にとって一番大切なことは,当該手法がきちんと,論 理構造を成す要素の開始点と終了点との関係を見いだせることであ る. この手法では,規格に則って作られたソフトウェアであっても,あ らゆる符号化データ上で,同じ検証処理を実行することは不可能で ある. スキーマ言語で規定された統語情報を使っても,空要素によって区 切られた範囲の内容モデルを確定することはできない. 79
- « 20.2 空要素を使った境界
- » 20.4 スタンドオフスタイル
- Home | 目次
20.3 仮想要素を使った分割・統合TEI: Fragmentation and Reconstitution of Virtual Elements¶
3つ目の手法は,ひとつの論理上の(入れ子化しない)要素を, 当該文書構造上,複数の要素に分割し,但し,それらを仮想上再構 築できるようにしておくものである. 例えば,直接引用となる節が,形式段落の中程から始まり,複数の 段落に渡り続いている場合,この節を一連の要素saidを,そ れぞれの要素pの中で使うことで示すことができる. 結果として得られたデータは,妥当なXML文書となっている. 但し,要素saidに記録されているテキストは,直接引 用を完全に(再)構成するための場所を示しているにすぎない. この様なことから,これらの要素は,時に,「部分的要素(partial element)」と呼ばれることがある.
<l>Catholic woman of twenty-seven with five children</l>
<l>And a first-rate body—pointed her finger</l>
<l>at the back of one certain man and asked me,</l>
<l>
<said n="quotation1">Is that guy a psychiatrist?</said> and by god he was!
<said n="quotation2">Yes,</said>
</l>
<l>She said, <said n="quotation2">He <emph>looks</emph> like a
psychiatrist.</said>
</l>
<l>Grown quiet, I looked at his pink back, and thought.</l>
</lg>
<s n="sentence1">Scorn not the sonnet;</s>
<s n="sentence2">critic, you have frowned,</s>
</l>
<l>
<s n="sentence2">Mindless of its just honours;</s>
<s n="sentence3">with this key</s>
</l>
<l>
<s n="sentence3">Shakespeare unlocked his heart;</s>
<s n="sentence4">the melody</s>
</l>
<l>
<s n="sentence4">Of this small lute gave ease to Petrarch's wound.</s>
</l>
この手法には,2つの問題がある.
ひとつは,この手法で記録されたデータには,テキスト中にある素
性よりも多い数の,素性を示す要素が存在していることになる.
例えば,「Scorn not the sonnet
」の例に
は,言語学上,4つの文が存在していることになるが,
要素sを
使い7つの範囲を記録することができる.
2つ目の問題は,意味的に誤解を起こしやすいことである. 例えば,「文」を示す要素を使って記録していたとしても,この例 では,要素s で記録されているテキスト素性が,言語学上の文を成しているとこ ろは,殆どない. 具体的には,「with this key」 は句であり,文ではない. また,「Of this small lute gave ease to Petrarch's woundは,統語範疇のひとつに対応する文字 列ではない.
以上のことから,これらの問題は,分割されている素性を自動的に 分析することを難しくしているといえる. 例えば,ワーズワースの詩にある文の数を調べようとしたとき,要 素sを完全な る修辞上の文を示すものとして数えてしまうと,本来の数よりも多 くなってしまう. また,その統語情報を分析しようとしたとしても,要素sを言語学上の 文を示すものと想定することができない.
Scorn not the sonnet」 を例にとってみよう. ここでは,文中にある分割された部分間の関係は, 16.7 総合で解説 されている,属性nextと属性prevを使い,明示されている.
<s>Scorn not the sonnet;</s>
<s next="#s2b" xml:id="s2a">critic, you have frowned,</s>
</l>
<l>
<s prev="#s2a" xml:id="s2b">Mindless of its just honours;</s>
<s next="#s3b" xml:id="s3a">with this key</s>
</l>
<l>
<s prev="#s3a" xml:id="s3b">Shakespeare unlocked his heart;</s>
<s next="#s4b" xml:id="s4a">the melody</s>
</l>
<l>
<s prev="#s4a" xml:id="s4b">Of this small lute gave ease to Petrarch's wound.</s>
</l>
<s>Scorn not the sonnet;</s>
<s part="I">critic, you have frowned,</s>
</l>
<l>
<s part="F">Mindless of its just honours;</s>
<s part="I">with this key</s>
</l>
<l>
<s part="F">Shakespeare unlocked his heart;</s>
<s part="I">the melody</s>
</l>
<l>
<s part="F">Of this small lute gave ease to Petrarch's wound.</s>
</l>
<l>
<s part="I">Catholic woman of twenty-seven with five children</s>
</l>
<l>
<s part="M">And a first-rate body—pointed her finger</s>
</l>
<l>
<s part="M">at the back of one certain man and asked me,</s>
</l>
<l>
<s part="F">"<s>Is that guy a psychiatrist?</s>" and by god he was!</s>
<s part="I">"<s part="I">Yes,</s>"</s>
</l>
<l>
<s part="F">She said, "<s part="F">He <emph>looks</emph> like a psychiatrist.</s>"</s>
</l>
<l>
<s>Grown quiet, I looked at his pink back, and thought.</s>
</l>
</lg>
<w xml:id="w01">Scorn</w>
<w xml:id="w02">not</w>
<w xml:id="w03">the</w>
<w xml:id="w04">sonnet</w>; <w xml:id="w05">critic</w>, <w xml:id="w06">you</w>
<w xml:id="w07">have</w>
<w xml:id="w08">frowned</w>,
</l>
<l>
<w xml:id="w09">Mindless</w>
<w xml:id="w10">of</w>
<w xml:id="w11">its</w>
<w xml:id="w12">just</w>
<w xml:id="w13">honours</w>; <w xml:id="w14">with</w>
<w xml:id="w15">this</w>
<w xml:id="w16">key</w>
</l>
<l>
<w xml:id="w17">Shakespeare</w>
<w xml:id="w18">unlocked</w>
<w xml:id="w19">his</w>
<w xml:id="w20">heart</w>; <w xml:id="w21">the</w>
<w xml:id="w22">melody</w>
</l>
<l>
<w xml:id="w23">Of</w>
<w xml:id="w24">this</w>
<w xml:id="w25">small</w>
<w xml:id="w26">lute</w>
<w xml:id="w27">gave</w>
<w xml:id="w28">ease</w>
<w xml:id="w29">to</w>
<w xml:id="w30">Petrarch's</w>
<w xml:id="w31">wound</w>.
</l>
<!-- Elsewhere in the document -->
<p>
<join result="s" scope="root" targets="#w01 #w02 #w03 #w04"/>
<join
result="s"
scope="root"
targets="#w05 #w06 #w07 #w08 #w09 #w10 #w11 #w12 #w13"/>
<join result="s" scope="root"
targets="#w14 #w15 #w16 #w17 #w18 #w19 #w20"/>
<join
result="s"
scope="root"
targets="#w21 #w22 #w23 #w24 #w25 #w26 #w27 #w28 #w29 #w30 #w31"/>
</p>
この,要素joinを使う手法は,TEIに準拠している.
分割して仮想上統合する手法の利点は,テキスト中にあるあらゆる 階層を明示的に扱うことができることである. 文書中で使われているひとつの階層構造と,分割され,統合される ことになる選択的な階層構造の両方を扱えることになる. この手法の欠点は,(他の手法と同様に)ひとつの階層構造に,他の 階層構造も合わせる必要があることである. そのように他の階層構造を統合する処理には,特別なものが必要と なり,要素joinを使う場合を除いて,意味的には誤解 を生みやすくなる.
20.4 スタンドオフスタイルTEI: Stand-off Markup¶
<w xml:id="w001">Scorn</w>
<w xml:id="w002">not</w>
<w xml:id="w003">the</w>
<w xml:id="w004">sonnet</w>;
<w xml:id="w005">critic</w>,
<w xml:id="w006">you</w>
<w xml:id="w007">have</w>
<w xml:id="w008">frowned</w>,
</l>
<l>
<w xml:id="w009">Mindless</w>
<w xml:id="w010">of</w>
<w xml:id="w011">its</w>
<w xml:id="w012">just</w>
<w xml:id="w013">honours</w>;
<w xml:id="w014">with</w>
<w xml:id="w015">this</w>
<w xml:id="w016">key</w>
</l>
<l>
<w xml:id="w017">Shakespeare</w>
<w xml:id="w018">unlocked</w>
<w xml:id="w019">his</w>
<w xml:id="w020">heart</w>;
<w xml:id="w021">the</w>
<w xml:id="w022">melody</w>
</l>
<l>
<w xml:id="w023">Of</w>
<w xml:id="w024">this</w>
<w xml:id="w025">small</w>
<w xml:id="w026">lute</w>
<w xml:id="w027">gave</w>
<w xml:id="w028">ease</w>
<w xml:id="w029">to</w>
<w xml:id="w030">Petrarch's</w>
<w xml:id="w031">wound</w>.
</l>
<!-- elsewhere in the document or in another document indicated by the value of @href -->
<p>
<s>
<include xmlns="http://www.example.org/ns/nonTEI" href="."
xpointer="range(element(w001),element(w004))"/>
</s>
<s>
<include xmlns="http://www.example.org/ns/nonTEI" href="."
xpointer="range(element(w005),element(w013))"/>
</s>
<s>
<include xmlns="http://www.example.org/ns/nonTEI" href="."
xpointer="range(element(w014),element(w020))"/>
</s>
<s>
<include xmlns="http://www.example.org/ns/nonTEI" href="."
xpointer="range(element(w021),element(w031))"/>
</s>
</p>
この方法は,先に紹介した要素joinととてもよく似ている. この方法の利点は,統合向けの要素sにある属性を特定することができること である. また,適切に処理してくれる既存のソフトウェアがあることも利点 である. スタンドオフスタイルの記述は,アノテーションが付加されるテキ スト部分が,単純なテキストデータのみ,つまり,XMLデータを含 まない場合でも使うことができる. この場合,マークアップされるテキストの範囲は,文字の位置によ り指定される(16.2.4 TEI XPointer.特に16.2.4.5 string-range()を参照のこと). 2つ目は,リンク先となるファイルの数である. 1つの(特別な)アノテーションを,他の全てのアノテーションの リンク先として使うことがある. また,記述の層をいくつも自由に結びつけることができる.
これまで,スタンドオフスタイルには,アノテーションを埋め込む ケースでは,いくつかの利点があるとしてきた. その中でも特に,元資料が書き込み不可の状態であっても,そのテ キストにアノテーションを付加することができるとは,利点である. また,アノテーションを含むファイルは,元テキスト上に記録す ることなく,自在に存在することができる. さらに,文学研究においては,不連続なテキスト部分に,ひとつの アノテーションを付加できるという利点や,独立した平行テキスト のそれぞれにアノテーションを付加できるという利点,そして,異 なるアノテーションのファイルに,複数の異なる種類の情報をまと めることができるという利点もある. 最後に,この手法はエレガントであるといわれてきたことを紹介し ておく.
但し,この手法にも,いくつかの欠点はある. 一つ目は,スタンドオフスタイルでは,情報を記録する複数の層が 存在することになるが,これは,それぞれ独立して解釈される必要 がある. 但し,各レイヤの情報は,独立してはいるものの,互いは依存関係 にある. また,複数の階層構造で示される情報を記録することはできるもの の,その情報には,一般的な手法では,たどり着くことは難しい.
TEI名前空間にはない要素を使っている限り,スタンドオフスタイ ルによる記録は,TEIの拡張の範囲となる.
- « 20.4 スタンドオフスタイル
- Home | 目次
20.5 XML以外の手法TEI: Non-XML-based Approaches¶
文章構造がオーバーラップする問題を解決したり,それに悩まない ような符号化の手法が,XML以外のものでは,多く存在している. このような手法には,全てを網羅するものではないが,以下のよう なものが提案されている.
- 共起要素をXMLにも導入するもの(Hilbert et al. (2005)). これは,SGMLにはあり,XMLからは外された素性CONCURを復活さ せるものである.
- 文書を表示する形式を1つ作り,複数の木構造が,その全体また はその部分を共有するもの. これにより,複数ある文書の視点が,ひとつの木構造を持つこと になる(Dekhtyar and Iacob (2005)).
- 「多彩XML(colored XML)」を使うもの(Jagadish et al. (2004)). これは,縒りXMLデータ(interwinded XML)として,情報をまとめ るものである. これにより,不要な冗長な記述を減らし,異なる階層構造へのパ スを保ちながらも,データベースを簡単に更新することができる ようになる.
- 「MultiX」を使うもの(Chatti et al. (2007)). これは,有向グラフで文書を表現する手法である. XMLでは,グラフを表現することができるので,少なくとも理屈 の上では,一般的なXML処理ソフトでも,このデータを扱うこと はできる.
- 一回きりの(Just-In-Time)XMLデータを使うもの(Durusau and O'Donnell (2002)). これは,データはXMLで記録されているが,一般的ではない方法 で,XMLデータを処理するものである. この方法では,XMLではないデータ構造への対応付けを認めてい る.
- LMNL(Layered Markup and Annotation Language)を使うもの. これは,XMLデータモデルや,その処理モデルに加え,XMLデータ へのシリアル化(訳注:XMLデータに戻すこと)の代替案を新たに提案し ている. これは,XMLに新しい表記法を採用し,Core Range代数に基づく データ構造を採用している(Tennison and Piez (2002)).
- MLCD(Markup Languages for Complex Documents)を使うもの. これは,非階層構造を表記する制約言語の草案,表記法 (TexMECS),データ構造(Goddag)を提案している. 詳細は,Huitfeldt and Sperberg-McQueen (2001)を参照のこと.
これらの手法は,一般的ではないXML処理ソフトやデータモデルに 基づいている. または,XMLデータではないものもある. TEIはXMLに基づいたものであるから,これらの手法の詳細は,この ガイドラインでは扱わない. TEIでこれらの手法を使う際には,拡張が必要となる. 多くの場合,その結果作られたデータは,TEIに準拠しないものと なる.
↑ Contents « 19 グラフ,ネットワーク,木 » 21 確信度・責任