
v XML入門
Contents
- « iv ガイドラインについて
- » vi 言語と文字集合
- Home | 目次
本ガイドラインで定義されている符号化スキームは,XML(Bray et al. (eds.)(2006))で定式化されている. XMLは,機器やシステムに依存しない規格として,電子形式のテキストを処理・蓄積するために広く使われている. また,Web世界のソフトウェアの多くが,データ交換用のフォーマットとしてXMLをサポートしている. この章では,XMLに関するいくつかの基本概念を紹介し,初めてTEIスキームを使う際に感じる疑問に答えることを目指している. TEIのより実践的な紹介は,本ガイドライン中の他の章, 23 TEIの使い方, 1 TEIの基礎構造, 22 ドキュメンテーション向け要素 にある.
正確に言えば,XMLは,メタ言語である. メタ言語とは,ある別の言語,例えば,マークアップ言語を記述するための 言語のことである. 歴史上,マークアップという言葉は, 編集者や入力者に対して,印刷やレイアウトを指定するために,注釈(アノテーション) や記号を,テキスト中に書き記すこととして使われてきた. 例えば,波下線は太字体を指示し,ある特別な記号は,テキストを 消したり,特定の字体での印字を指定するなどである. テキストの整形や印刷を自動化する際,このような指定は,特 別な記号として電子テキスト中で扱われ,整形・印刷などの処理が施されることになる.
この意味で,「マークアップ」または「符号化」は,テキストへの ある解釈を明示化する手段と定義することができる. もちろん,印刷されているテキストには,この意味で,必ず何らか の符号化(またはマークアップ)が暗示的に施されている. 例えば,句読点,大文字,ページ周りの文字処理,語間の空白など, 全てが,マークアップされていると見なすことができるだろう. これにより,人はテキストを読む際に,どこまでが単語であるか,ど れが見出しであるか,統語上関係する文はどれか,などを知る助け になっている. 計算機上で処理することを目的に,テキストを符号化することは, のんべんだらりと書かれた文字列( scriptio continua 2) から,単語を切り出すようなもの である. 暗黙にあるものを明示化する処理であり,このテキスト内容をど のように解釈すべきか(または解釈されてきたのか)を読者に示す 処理である.
「マークアップ言語」とは,符号化するテキストと,その約束事の 集まりである. マークアップ言語には,1)マークアップがどのように地の文と区別され るか,2)どのようなマークアップが使えるのか,3)どのマークアップが必須なのか, 4)そのマークアップは何を意味するのかが,必ず定義されている. XMLでは,このうち,はじめの3つを定義する手法が備えられている. これらを解説するドキュメンテーションは,4)向けのものといえる.
この章では,本ガイドラインを実践するために必要となる,XMLの 機能を紹介する. XMLに関心のある読者は,多くの書籍やwebサイトも参照した方がよ い. 3
v.i XMLの特徴 TEI: XMLの特徴 ¶
- 手続き的ではなく,記述的である.
- 文書とは,文書型のインスタンスである.
- ハードウェアとソフトウェアから完全に独立している.
- XMLには,拡張性がある. HTMLのように,使うタグが規定されていない.
- XML文書は,構文的に整形な式である.
- XML文書は,スキーマに対して妥当なものとなることができる.
- XMLは,データの表示法ではなく,データの意味に関心を払うものである.
記述的マークアップ TEI: 記述的マークアップ¶
記述的マークアップは,文書を区分するために使われる. paraや\end{list}のよう なマークアップは,文書のある特定部分を示すもので,例えば「ここ から先は段落である」「ここで直近のリストが終わる」という ことを示している. 一方,手続き的マークアップの場合は,文書中の特定カ所でど のような処理を施すかが示されている. 例えば,「ここを,パラメータ42, b, xで段落処理をする」 「左マージンを2クワタ左へ,右マージンを2クワタ右へ,1行飛ばして 下へ移動し,新しく左マージンへ移動」などである. XMLでは,文書中に特定の処理を施す命令と,それを示すマー クアップは,別のものとされる.
一般に,文書に処理を施すためのマークアップや記述は,当該 文書とは別のデータに置かれる. その典型例は,スタイルシートである. スタイルシートは,時に,単なる表示以上の指定をすることが ある. 4
記述的マークアップは,同じ文書が,必要とされる部分を対象 に,多様に処理されることがある. 例えば,内容分析プログラムでは,アノテートされたテキスト 中の脚注は全て無視されるが,書式付けプログラムでは,それ らは集められ,章末にまとめられる. あるファイルの同じ部分データに異なる処理が施されることは可能である. 例えば,あるプログラムでは,人物や場所の名前を文書中から 抽出し,索引やデータベースを作ることもあるし,また,別の プログラムでは,同じ文書に対して,違うスタイルシートを使 うことで,異なる印字で,人物や場所の名前を印刷することも ある.
文書型TEI: 文書型¶
XMLの2つ目の特徴は,文書型である. 文書には,型があるとされている. 型とは,計算機で扱うデータの種類のようなものである. 文書型は,構成要素と構造から定義される. 例えば,「レポート」とは,「題目」「著者」「要旨」それと 一連の「段落」から構成されていると考えられる. 題目がないものは,この定義からすると,レポートとはいえな い. また,一連の段落の後に要旨がくるものは,例えレポートのよ うな体裁を繕っていても,ひとにとっては,それはレポートと はいえないだろう.
文書の型が既に知られているのであれば,パーサというソフトウェア は,その文書型の定義が与えられていれば,それに相応しい文 書であるかを確認することが出来る. パーサは,特定の要素のみが当該文書中に存在しているのか,それらは適切に関連づけられているか,正しく並べられているのかなどを確認することになる. より重要なのは,同じ文書型の異なる文書を,同じように処理することができることである. ソフトウェアは,文書型の情報から得られる知識を使い,より「知的な」振る舞いをするように作ることが出来る.
データ独立TEI: データ独立¶
XMLが開発された基本デザインは,ある目的で符号化された文書を,ハードウェアやソフトウェア環境に依存せずに,不足なく,他に渡すことが出来ることを保証することにある. これまでの説明にあった2つの特徴は,抽象レベルで,この要求を満たすためものである. XMLの3つ目の特徴は,文書をマークアップする文字列レベルのものである. XML文書は,どのような言語や書記システムで書かれていても,同じ符号化文字で書かれている(つまり,ある書記システムを担う図形文字を指示するバイナリデータを表現するしくみである). 5 この符号化方式は,国際規格で定義されている. 6 通称ユニコードと呼ばれているこの世界的な文字集合は,メーカーの団体であ るユニコードコンソーシアムが策定している. 7 このユニコードは,世界中の古今の書記システムを網羅する,多くの記号を表示するための規格である.
現在ある計算機システムの殆どが,ユニコードをサポートしている. ユニコードに対応していない計算機システムに対して,XMLは,数字を使い,間接的に1つの文字を指示する手法を用意している.これは,文字参照と呼ばれている手法で,詳しくは 文字参照のところで解説する.
- « v.i XMLの特徴
- » v.iii XMLの構造
- Home | 目次
v.ii 文書構造 TEI: 文書構造¶
テキストとは,単なる連続したバイトではなく,のんべんだらり と連なる単語でもない. テキストは,目的にあわせて,種類も大きさも異なる単位へと分割されること が出来る. 例えば,散文形式のテキストは,章,節,段落,文へと分割する ことが出来る. 韻文形式のテキストも,編,連,行へと分割することが出来る. 印刷されたテキストは,巻,丁,ページと分割することが出来る.
この様な構造の単位は,テキスト中の特定の場所を示す際によく 使われている(例えば,10章2段落の3行目とか,10連1234行目, 412ページなど). また,この様な単位は,分析のために,意味的なまとまりへと分 割することもできる(例えば,2章にある文の平均的な長さは,5 章のそれと異なるとか,いくつの段落が単語"nature"を含んでい るか,何ページあるのか,など). 構造上の単位は,テキスト中にある部分を特徴付ける点で,より 分析的なものである. 舞台芸術に関するテキストでは,登場人物毎の発話は,ある独立 した単位と見なすことが可能で,ト書きや動きに関する記述も, また別な単位と見なすことができる. このような分析では,テキスト中のどの場所(例えば,2幕でホレイ ショの93番目の科白)にあるのかはさほど重要ではなく,むしろ,登場人物 同士で同じ単語がどのように使われているかを比較したり,同じ 登場人物が異なる場面で同じ言葉をどのように使うのかを比較す るときに役立つ.
散文でも同様に,直接話法と間接話法の違いや,スタイルの違い (例えば,物語,討論,解説,論議など),作者の違いで,それぞ れを異なる種類の単位と見なすことがある. また,ある種の分析(特に校合)では,ある特定の印刷,または手 書き資料の外形が重要になってくる. 逆説的ではあるが,そのような字体,行,空白などの様子を記述 するために,記述的マークアップを使うことがある.
このようなテキスト構造は,複雑で見通しのきかない方法で,他 の単位とオーバーラップしている. とりわけ,出版文化の中で生み出されたテキストの場合には,物 理的な構造と論理的な構造の存在を,共に認識しておく必要がある. 多くの偉大な作品(例えば,スターンのトリストラム・シャンディ)は,物語文の単位と (例えば,章や段落),外形の単位(例えばページ区切)の相互作 用を意識せずに鑑賞することなどできない. 異なるレベル間にある相互作用というものは,研究者にとって重 要なものである. 例えば,統語構造や発話構造がどのように調和し,または調和し ていないのか,音韻構造が形態素からどの程度影響されているの かなどである.
v.iii XML構造TEI: XML構造¶
この節では,テキスト構造を特定し,マークアップする,簡単だが一貫したXMLの手法を解説する. また,文書構造が意味上どのように構成されているのかを定義す るために使われる,XMLが提供する表現規則も解説する.
要素TEI: 要素¶
XMLにおける,構造の構成要素をしめす専門用語を「要素」 という. 異なる種類の要素には,異なる名前が与えられている. 但し,XMLには,要素間の関連を示す仕組みしかなく,要素の 意味を表現する手段はない. 例えば,要素blortは,要素 farbleの中に出現することができる (または,できない)とか,要素 blortetteを子要素として持つ(また は,持てない)とかを表現できる. XMLは,ソフトウェアから独立していることから,テキスト要 素の意味には,全く関与しない. どのような要素名を付けるのか,それにどのような意味を期待 するのか,ということは,XMLの語彙を決めるユーザーの手 に委ねられている. ここに,本ガイドラインのような文書の主たる目的がある. ある要素の種類を示す名前を,専門用語で「共通識別子(GI)」 という.
remarks <quote>This is the silliest stuff that ere I heard
of!</quote> clearly indicate ..
内容モデルの例 TEI: 内容モデルの例¶
要素は空である,つまり,内容がないこともある. 要素は,要素を含まない文字列のみを内容として持つこともある. 但し,多くの場合,要素は,別の要素を埋め込んで(含んで)いる.
<poem><heading>The SICK ROSE</heading>
<stanza>
<line>O Rose thou art sick.</line>
<line>The invisibleworm,</line>
<line>That flies in the night</line>
<line>In the howling storm:</line>
</stanza>
<stanza>
<line>Has found out thy bed</line>
<line>Of crimson joy:</line>
<line>And his dark secret love</line>
<line>Does thy life destroy.</line>
</stanza>
</poem>
<!-- more poems go here -->
</anthology>
<!-- more poems go here -->
- 文書全体は,ひとつの要素としてある. この要素をルート要素という (この例ではanthologyが相当す る).
- どの要素も,ルート要素の中にある. また,ルート要素を除く全ての要素は,ひとつの親要素を持つ. 要素同士がオーバーラップする(重なり合う)ことはない.
- タグは,要素の始まりと終わりを,明示的にマークする.
整形式XML文書には,様々な処理を施すことができる. 例えば,索引を作るソフトウェアでは,詩の中にある見出しや, 最初の行や単語のリストを作るために,必要な要素を抽出する ことができる. また,簡単な書式付けソフトウェアでは,連の間に空間を挿入 したり,各連の最初の行をインデントしたり,連番号を付加したりするこ とができる. 詩の中の異なる部分に,異なる字体を割り振ることもできる. また,分析ソフトウェアでは,句読点記号を,連や韻律の単位 関連づけることができるだろう. 11 この様なソフトウェアを使うと,例えば,詩の編集者による連や行の違いに関心のある研究者にとっては, タグを操作することで,それを容易に知ることができるだろう. もちろん,そのようなテキストは,ある計算機から別の計算 機へと移送することも可能であり,タグを処理できるソフト ウェア(または人)であれば,ワープロで作られたデータを移 植する際には必要となる変形や変換処理を施す必要なく扱 うことができる.
名前空間は,名前が所属するグループを表記する手段を提供する が,その名前付与規則を確認する手段を提供するものではない. 整形式だけが,文書のマークアップの利便性を上げるものではな い. 例えば,電子作品集を作る際に,計算機システムが,どのように 連や行,見出しが共起しているのかを確認してくれると,便利で ある. もし,この時のシステムが,連には要素 stanzaをタグ付けし, 決して要素 cantoや Stanzaを付加しないのであれば, より便利なものとなるだろう. このように,ある規則に従って作られているかを検証された文書 を,妥当な文書と呼んでいる. このような妥当性を検証できることも,XMLの利点のひとつであ る. この様な検証には,形式的に書かれた規則が必要である. XMLの場合,この様な形式的な規則は,スキーマと呼ば れる,付加的な文書で定義される. 12
XML文書の検証 TEI: XML文書の検証¶
スキーマのデザインは,緩やかに規定することも,細かく規定するこ ともできる. このバランスを考えると,以下にあるような簡単な規則と,現実にあるテ キストを処理するという複雑さ間で,身動きが取れなくなるにち がいない. とりわけ,既に存在するテキストに対して規則を当てはめるとき, そのようになる. スキーマのデザインを決める人が,はるか昔のテキストに隠された元々 の意図や意味がはっきりとは解らないまま,その構造にある規則 を決めることは,とても難しい作業となる. 一方,例えば,データベースに入れることを前提に,ある規格に則っ て作られた新しいテキストがある場合には,その規則を厳密に決 めるほど,よりその効果は発揮されることになる. また,既存のテキストにマークを付加する場合においても,想定されるテキストについて厳密な規則を定義すれば,それを検証する際に,有効な手段となる. 小さなプロジェクトでは,スキーマに対して,多くの人が参加する大規模なプロジェクトとは異なるスタンスと取ることになるだろう. いずれにせよ,重要なことは,スキーマはテキストを解釈した結 果から得られるものである. 全てのテキストで絶対的に正しい,単一のスキーマなど存在しな い. 但し,ある特定の分析向けに,あるスキーマを優先的に使うこと は便利である.
XMLは,文書構造を統一したいと思うところで,広く使われてい る. 例えば,技術文書を書く時に,節の上下関係を,適切に入れ子の 関係にしておくことは,極めて重要であり,また,相互参照を適 切に処理することも大切である. この様な場合に,文書は,既定の規則に従っているかが確認され る,原材料とみなされる. 但し,厳密に統制される必要のない要素に対しては,単純な規則で済ませることも出来る. このような規則を明確に規定することで,研究者は,電子テキス トにタグ付けし,検証する作業を軽減させることができる. また,それは同時に,研究者には,符号化されるテキストが持つ構 造や,重要な特徴についての解釈を明確にすることも求められてくる.
スキーマの例TEI: スキーマの例¶
スキーマは,様々な方法で記述される. よく使われるのは,文書型定義(DTD)という,XMLがSGMLから引き 継いた方法である. また,W3Cで策定されたXML Schemaという言語もある( http://www.w3.org/XML/Schema). また,OASISという団体で開発され,現在はISO規格になっている RELAX NGという言語もある. 13. 本章も含めて,本ガイドラインでは,RELAX NGの簡易表記を使っ て例を紹介する. 但し,本ガイドラインで規定された内容は,どのスキーマ言語か らも独立したものになっている. 14 以下では,RELAX NGの簡易表記を使うことになるが,別のスキー マ言語を使っても,表現できることに注意して欲しい.
poem_p = element poem {heading_p?, stanza_p+ }
stanza_p = element stanza {line_p+}
heading_p = element heading { text }
line_p = element line { text }
start = anthology_p
RELAX NGを使ったスキーマの書き方には,これ以外の表現方法も 可能であることに注意して欲しい. 15 ここでは,ガイドライン全体で使われる表現方法として,この ような書き方を採用している.
RELAX NGスキーマでは,可能な文書構造を,パタン を使い規定してゆく. RELAX NGスキーマでは,複数のパタンを定義してゆく. パタンは,入力される文書がマッチするテンプレートの役割を果 たすものである. パタンの意味は,他のパタンを参照することで定義されている. または,既定の基本概念を参照することでも定義される. これについては,後述する. 先の例では,イコール記号の左側にあるのがパタンの名前であり, 右側にあるのが,その意味の宣言になる. パタンは,特別な型を取ることもある. 例えば,要素パタン,属性パタンというものがある. 先の例には,4つ(訳注:5つ)の要素パタンがある. パタンの名前と,そのパタンが記述する属性の名前が,同じよう に書かれていることに注意すること. 例えば, anthology_p = element anthology {poem_p+} では,要素パタンの名前としてanthology_pが, そのパタンが定義する要素名としてanthologyが使われ ている. このような名前の付け方自体は,さほど重要ではない. パタンと要素に同じ名前を付けることは可能であり,その場合で も,この2つは,統語上,全く別のものである. キーワード'element'の次に,要素名,すなわち共通識別子 (GI)が書かれ,要素内容は波括弧の中に定義される. これらの詳細については,以下で解説する.
先の例にある,一番最後の行は,RELAX NG検証ソフトに,どの要素が ルート要素であるかを教えるためのものである. この場合,要素anthologyが,それに 該当する. これにより,検証ソフトは,当該文書が整形式であるが妥当ではない, 等を確認することが出来る. これは,処理作業の開始点を示すともいえる.
共通識別子TEI: 共通識別子¶
パタンの宣言では,キーワード'element'に続いて,要素の共通識別 子(GI)が記述される. 例えば,先の例では, poemや headingなどがそうである. 共通識別子(GI)は,英数字,ハイフン,下線,ピリオドから作 られ(訳注:正確な記述ではない.XML規格書を参照すべき), 必ず文字から始められる. 16 大文字と小文字は区別されるため,例えば共通識別子(GI) fooとFooとは,異なる要素となる. ちなみに,TEIに準拠する文書のルート要素は, TEIであり, teiではない.
内容モデルTEI: 内容モデ¶
パタンの意味を宣言する部分の,2つめの構成要素は,波括弧 で括られた宣言部分で,これは内容モデルと呼ばれ ている. 内容モデルでは,当該要素に含まれる中身を規定している. RELAX NGでは,内容モデルを,パタンを埋め込んだり,(上記 の例のように)パタンの名前を参照する方法で定義している. RELAX NGの簡易表記では,他の要素内容を特定するために,い くつかの予約語を使うことがある. そのうち,もっともよく使われるのは,上記の例にもある, textである. 予約語'text'は,当該要素には,正当な文字のみが含まれ,要 素は含まれていないことを意味している. 例えば,XML文書を,家系図のように捉えて,ひとつ祖先から すべてが発生していると考えてみる. この時,要素anthologyは,そのひ とつの祖先に該当し,そこから子孫が生まれ(この例では, anthologyの次が poemで,次に stanza,その次に, line,そしてheading),その一番最後に textにたどり着くイメージである. 先の例では,要素headingと lineの内容モデルには,'text'だけ が定義され,要素は定義されていない.
出現回数記号TEI: 出現回数記号¶
先の例では,要素stanzaは,1つ以上 の行から構成されていると宣言されている. 出現回数記号(「+(プラス)」記号)により,パタン line_pが何回繰り返されるかが示されている. 出現回数記号には,「+」「?」「*」の3種類ある. 「+」は,当該パタンが1回以上出現することを示す. 「?」は,当該パタンが出現するとすれば高々1回であることを 示す. 「*」は,当該パタンが出現しないかまたは1回以上出現するこ とを示す. 例えば,stanzaの内容モデルが {line_p*}とすれば,行は1つもないかもしれないし, 1行以上あるかもしれない. また,例えば,内容モデルが{line_p?}であるとすれ ば,行を含んでいないかもしれないが,1行を超える内容を含 んではいない. 上の例にある要素poemの宣言 は,poemとして2つ以上の見出し (heading)をとることはなく,時に,見出しはない場合もある こと,さらに,少なくとも1つ,時には複数の連(stanza)をとることを示している.
接続記号TEI:接続記号¶
内容モデル{heading_p?, stanza_p+}は,複数の構成 要素を含み,その出現順序は,先にheading_pが出現し,続いて stanza_pが出現することが規定され ている. このような出現順序は,構成要素間にある「接続記号(,)」で示されている. 出現記号には,「,」と「|」の2種類ある. 「,」は,一連の順番を示し,「|」は,選択的であることを示 す. 先の例にあるコンマ(,)を「|」に変えたとすると,見出し (heading)または連(stanza)のどちらかをとり,その両方はと ることができない.
グループTEI: グループ¶
element firstLine {text}
secondLine_p = element secondLine {text}
{ heading_p?, (stanza_p+ | couplet_p+ | line_p+) }
{heading_p?, (stanza_p | couplet_p | line_p)+ }
line { (text | name_p )* }
XMLでは,混合内容の定義の仕方に,ある制約を加えている. それは,もしテキストが内容モデル中に他の要素と共に出現する 際には,常に,一番外側のグループの一番始めに,1回だけ, 出現しなければならない,という制約である. もし,当該グループが繰り返される場合には,必ず「*」で指 定する必要がある. 19
poem_p = element poem {heading_p?, ( line_p+ | (refrain_p?, (stanza_p, refrain_p?)+ )) }
element poem {heading_p?, (line_p|refrain_p|stanza_p)+ }
- « v.iii XMLの構造
- » v.v 属性
- Home | 目次
v.iv 複雑な例TEI: 複雑な例¶
これまでの例では,文書構造中の要素は,直接指定できるとしてきた. 例えば,詩は連からなり,作品集は詩からなるとしてきた. 連は,詩の前後に出現することはなく,他の無関係な要素と共に出 現することもない. 詩は,作品集を含むことはできない. 文書型に埋め込まれている要素は,1つの祖先から多くの子孫(殆ど はテキストデータを含む要素)へとつながる家系図のような階層構 造に表現し直すことが可能である. 例えば,2つの詩からなる作品集で,はじめの詩は2つの四行連から, ふたつめの詩は1つの連からなっているとする. これは,以下のような木構造で表現することが可能である.
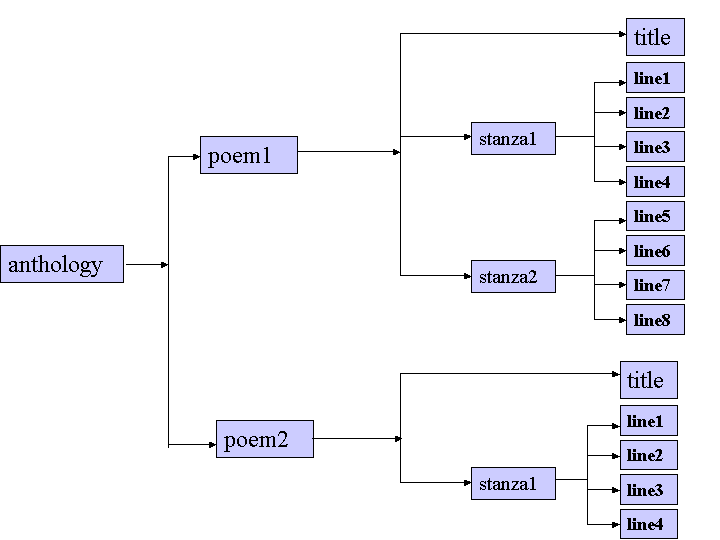
このXML文書の構造を示した図は,XML処理システムが想定する抽象モデルと似たものである. そのようなXML処理システムでは,XML文書の部分を指定する, 規格化された手法として,XPathを使用している. 20 XPathでは,XML文書の部分を参照する,図的でない(訳注:文字 記号による)表現方法を提供している. 例えば,ブレークの詩の最後の行を, 「/anthology/poem[1]/stanza[2]/line[8]」という具 合に参照することが可能である. 角括弧([])は,数値による選択を示している. ここでは,1番目の詩の,2番目の連の,8番目の行を示している. もし,この角括弧を全て外したとすると,残ったXPathの表現は,作 品中にある詩の連に含まれている,全ての行を示すことになる. XPathでは,任意の要素の集合を示すことができる. 例えば,「/anthology/poem」では,作品集にある全ての詩 を示すことになり,また,「/anthology/poem/heading」で は,全ての見出しを示すことになる.
XPathで使われているスラッシュ記号「/」は,ファイル名を示す際 に使われる「/」や「\」と同じようなものである. すなわち,「/」の左側の項目が,「/」の右側の項目を含んでいる関 係が示されている. XPathでは,「/」を繰り返すことで,中間にある項目をいくつでも示 すことが可能である. 例えば,「/anthology/poem//line[1]」という表現では, どのような連(stanza)かを問わず,作品集にある詩における第1行目 を示している.
作品集の構造を示すこのような木構造は,他にも考えられることは 確かである. 先に使った木構造もさらに細かく分けることも可能で,例えば,行 を構成する単語は行をまたぐことはないので,行をさらに単語へと 分割することも可能である. このようにテキストを単純な構造(これを通称OHCO( ordered hierarchy of content objects)と呼んでいる, Renear et al.21)と見立てることには,驚くべきこ とに,多くの目的で効果的なものとなる. もちろん,これだけでは,現実にあるテキスト構造の複雑さには 十分には対応しきれず,より複雑な仕組みが必要となる. これまでに見てきた作品集のモデルには当てはまらないような木 構造も沢山考えることができる. 例えば,韻文としての構造とは異なる統語構造や他の言語学上の項目に注目することもあるだろう. また,より簡単な例としては,同一テキストの異なる版では,ペー ジ立てを別に表現することもあるだろう.
OHCOモデルでは,複数の異なる木構造が同じ文書中で現れ,異なる 要素同士がオーバーラップするようなケースを表現することが困難 である. 文書中でマークアップされている要素は,それがどの名前空間に属 していようとも,ひとつの階層構造を構成している. 従って,オーバーラップしている構造を示すためには,まず,ある ひとつの階層構造を選択し,その後,他の階層構造と重なるポイン トをマークアップする必要がある. 例えば,韻文の構造を先に定義したが,そこにページ割りの情報を 加えるには,ページとページの間に,空要素のマークアップを挿入 することができる. もしくは,本ガイドラインの 16 リンク,分割,統合にあるよう, 選択的に,別の構造を,リンクの機能を使い表示することも可能である. これらの機能は全て属性により活性化する. 属性を使い,特定の要素を指定し,かつ,それらを任意の構造へと参照・ リンク・関連づけすることになる.
- « v.iv 複雑な例
- » v.vi 他の構成要素
- Home | 目次
v.v 属性TEI: 属性¶
XMLでは,「属性」という用語を,特別な技術的な意味合いで使っている. 属性は,当該要素の,内容ではなく,その出現そのものについての 記述的な意味を示すために使われている. 例えば,属性statusをある要素に加え ることで,その信頼度を示すこともあるし,また, 属性identifierにより,文書中の特定 要素を示すことをがある. 属性は,これらの状況では,極めて便利に使うことができる.
同じ名前の属性を,異なる要素で使うことも可能である(例えば, TEIスキームでは,どの要素でも属性n を使うことができる). この時,それぞれの属性は,異なるものとして扱われる. 従って,そこには,異なる値が付与されても良い. 要素に属性に付与するには,「属性名-属性値」のペアの 形で,要素の開始タグ中に記述される. 要素の終了タグには,「属性名-属性値」による属性の記述を書く ことができない.
「属性名-属性値」で示される属性間の順番は,重要ではない. 但し,それぞれの属性は,1つ以上の空白(すなわち,スペース,改 行,タブ)で区切られる必要がある. 属性値は,必ず,二重または一重引用符でくくられる必要がある.
属性リスト宣言TEI: 属性リスト宣言¶
属性は,スキーマの中で,要素と似た形で宣言される. 属性の名前と,それが付加される要素が特定され,さらに,取り 得る属性値の種類を指定することができる.
attribute status {"draft" | "revised" | "published"}
属性が取り得る値を定義しているパタンは,要素パタンの時と同 様に,波括弧で括られている. 先の例では,属性値は明示されている3つのうちから,ひとつを 選択する必要がある.
attribute status {text}
- ブール型
- 真または偽.
- 数値
- 数値による量の表示.
- 日付
- ある暦システムに従った日付や時間の表示.
これらに加えて,ID型と呼ばれる,識別子を値とするデータ型と, URI型が,XML文書を管理する際には便利なものとして使われている. この詳細は,次の節で解説する.
識別子TEI: Identifiers and indicators¶
テキスト要素を参照することはよくあることで,例えば, 「注6を参照」「詳細は5章で」のような場合である. 文書を書いている段階では,このような参照先のテキスト要素に 関連づけられている注釈や章の番号は,決められていないことが ある. このような表示上,重要とされるページ番号や章の番号を記録す る時,もし,記述的マークアップを使うのであれば,これらはマー クアップ中に入力されることはない. 入力されるとすれば,本文としてあるテキスト中である(但し, 処理するソフトによっては,これも異なるかもしれない). XMLでは,他の場所から参照されるために使われるラベルである, 特別な識別子を伴う要素を示す属性が用意されている. この属性はXML名前空間を使い, xml:idとして,定義されている. 従って,これは,TEIスキーマのどこでも使うことが可能である. この属性は,識別子としての役割を持つことから,その属性値は, 当該文書の中でユニークな値でなければならない. 相互参照は,スキーマ中で宣言される特別な属性を持つ要素とし て定義されることになる.
</poem>
<poem xml:id="P40">
</poem>
<poem>
</poem>
要素poemRefは,要素内容を持たず, 属性targetのみが定義されている. この属性値は,必ず識別子またはURIである. 22 また,この定義には,属性パタンになにも付加記号が付いてい ないことから,要素poemRefは, 必ずこの属性をとる必要がある.
<poemRef target='#Rose'/> ...
この様に符号化されたリンクを,ソフトウェアが見つけた場合, 様々な動きをすることが考えられる. 例えば,フォーマッタは,同じ文書中にある詩のページや行への 参照を構築したり,それを挿入したり,見出しや第一行目 を引用したり,などをすることがあるだろう. ハイパーテキストを実現するソフトウェアでは,参照された詩へ リンクを作ることになるだろう. XMLの目的は,相互参照の存在を示すことにあり,その具体的な 処理を指定することは目的ではない.
属性は,XML文書中で,要素と同じく,構造の構成要素となること から,XPathを使い,属性にアクセスすることができる. 例えば,作品集にある,属性statusの 値がdraftである全ての詩を参照する際には,XPathを /anthology/poem[@status='draft']とすればよい. また,そのような詩の見出しを参照するときには,XPathを /anthology/poem[@status='draft']/heading とすればよい.
- « v.v 属性
- » v.vii 関連づけ
- Home | 目次
v.vi 他の構成要素TEI: Other components of an XML document¶
これまでに紹介した要素や属性に加えて,XML文書では他にも,形 式上異なる単位がある. XML文書には,妥当性を検証するソフトウェアが,その検証をする前 に,参照を解決することになる決まった文字列がある. これを通称,「エンティティ参照」と呼んでいる. エンティティ参照は,「ボイラープレート」つまり,よく使う決ま り文句でありながら,簡単にはキーボードから入力できないような 文字列を表現する手段として有効である. XML文書には,あるソフトウェアに特定の処理をさせたいときに, それを示す任意の標識,またはフラグを挿入することができる. 例えば,フォーマッタに,ある場所からは新しいページに変えさせ る時などである. この様なフラグを,通称「PI(処理命令)」と呼んでいる. 更に,XML文書には,先にも紹介した「名前空間」という手段を使 い,別の要素を取り入れることもできる. この節では,以上の3種類について解説する.
文字参照TEI: Character References¶
XML文書は,その内部で,文字は同じ符号化方式(訳注:Unicode) を採用している. しかしながら,現行では,全てのコンピュータシステムがこの符 号化方式を直接サポートしているとは限らない. そこで,XMLでは,Unicode文字を,10進数や16進数による数値表 現を使って表現する,特別な書式が用意されている.
例えば,文字éは,Unicodeの 文字としては,16進数の数値で00E9と表現できるが, この文字がXML文書中に入力されていると考えてみる. もし,この文書が,この文字をサポートしていないシステム上で 使う(または入力)する場合,この文字を,文字参照 é(記号xは,以下の数値が16進数であるこ とを示している),またはé(これは10進数) による表記)として表現することが出来る. この種のエンティティ参照は,事前に定義をしておく必要はない. なぜならば,XMLの内部で想定する符号化方式は同じだからであ る.
読みやすさを考慮して,文字参照に覚えやすい名前(例 えば,eacute)を使うことも可能である. その際には,「エンティティ宣言」と呼ばれる方法 を使い,その名前とUnicode上の番号が対応付けられる必要があ る. また,いくつかの文字参照は,事前にXML中で宣言しておく必要 なく,覚えやすい文字を使い,参照することができる. このような文字参照としては,例えば「アンド記号」や「小なり 記号」などがある. これらの記号は,この仕組みがなければ,簡単にはXML文書中に 挿入することが出来ないものである.
名前による文字エンティティ参照は,どれも「アンド 記号」から始まり,続く「名前」「セミコロン」から構成されて いる. 例えば,文字列‘T&C’をXML文章に含みたいときには, T&Cと入力することになる. この様な文字参照には,他にも,< (<) や'(')がある.
"Text Encoding Initiative">
PITEI: Processing instructions¶
XMLが作られた背景には,個別の文書処理に関する情報を排除す るという目的があったが,そのような情報を利用することは,時 に大変便利なことがある. 但し,そのような場合でも,文書構造とは明白に分けられる場合 に限ってである. 例えば,先の例にあるような,XML文書を印刷する際に,フォー マッタに対して,新しいページの開始場所を示す情報を伝える時 である. 一般に,ページ替えは,フォーマッタが独自に判断するものであ るが,この判断を覆したい時もあるだろう. XMLにおいて,PIは,文書中に挿入され,そのような指示を,他 のマークアップタグに影響を与えることなく,とても単純で,か つ効果的な方法を提供するものである.
名前空間TEI: Namespaces¶
妥当なXML文書には,必ずスキーマが指定されている. スキーマでは,当該文書の構成要素となる要素が定義されている. しかし,整形式XML文書は,必ずしもスキーマが指定されている 必要はない(スキーマが存在しないこともある). それでも,使われている要素名の由来が定義されていることは, 便利である. また,別のスキーマで(恐らく違うように)定義されている要素を, 文書中で使うときには,要素を定義しておくことは,なおさら望ましい. 木工職人が定義した要素 table と,記録係が定義したそれとでは,その中身が異なるのは,もっ ともなことであろう.
「名前空間」がXMLに導入された背景には,この問題についての 対処法として,導入された経緯がある. 仮に,XML文書が,ある言語で書かれていたとすれば,その名前 空間には,その言語の単語が使われていると考えることができる. ある文書中に,複数の言語の単語を含めることが出来るように, 整形式XML文書にも,他の名前空間にある異なる要素を含めるこ とも可能である. 名前空間は,当該要素が所属する集合,すなわち定義されているスキーマを示す 点では,スキーマと似ている. 但し,スキーマは,要素の定義がまとめられているが,名前空間 は,単に,要素集合の存在を示すだけである. すなわち,XML文書中に実存するものは,弁別的な「接頭辞」の みであり,その接頭辞と関連する,識別のための「名前」だけである.
例えば,作品集に,ある複雑な図表を挿入することを考えてみる. この時,まず考えることは,矢や多角形などの図形要素向けのXML マークアップを,現在使っているスキーマを拡張するかどうかである. XMLには,テキストの構造を表現するだけでなく,図表もテキスト と同じように取り入れることが出来るという利点がある.
幸いにも,この様な図表を取り入れるために,新しくスキーマを 作り出す必要はない. 例えば,W3Cで定義されたSVG言語という,図形向けのマークアッ プ言語が既に存在している. 23 SVGは,XMLを使い,2Dの図を表現するもので,大変よく利用さ れ,多くのソフトウェアでサポートされている. SVGに対応したソフトウェアを使うことで,簡単に図を書くこ とができ,しかもそれを,作品集の中に,XML形式で保存す ることが可能である. この時,SVGソフトウェアが,自分たちが定義した要素 lineと,SVGにある,恐 らく自分たちのとは異なる定義をしてある要素 lineを混乱しないようにする には,当該文書中に,SVGの名前区間にある要素が含まれてい ることを示す必要がある.
...
</anthology>
<!-- anthology markup elements here -->
<!-- more anthology markup elements here -->
</anthology>
xmlns:svg="http://www.w3.org/2000/svg">
<!-- anthology markup elements here -->
<svg:svg>
<!-- SVG markup elements here -->
</svg:svg>
<!-- more anthology markup elements here -->
</anthology>
xmlns:gram="http://www.gram.org"
xmlns:svg="http://www.w3.org/2000/svg">
<!-- anthology markup elements here -->
<svg:svg>
<!-- SVG markup elements here -->
</svg:svg>
<line>
<gram:itj>O</gram:itj>
<gram:nom>Rose</gram:nom>
<gram:pron>thou</gram:pron>
<gram:aux>art</gram:aux >
<gram:adj>sick</gram:adj>
</line>
</anthology>
マーク付きセクションTEI: Marked Sections¶
先に解説したように,XMLでは,XMLの文法で使われている文字(例 えば,小なり記号やアンド記号)を単に入力する,すなわち,タグ の開始を示すものでなく,エンティティ参照を示すものでもない文 字として入力する際には,特別なことをする必要がある. その1つの方法は,既定のエンティティ&や <を使うことである. 但し,この方法は,そのような文字が多くないときに使われる手段 である. もし,そのような文字の数が多い場合,例えば,このガイドライン を記述するXML文書のように,数多くのXMLマークアップの例が含ま れている場合には,他の手段を使うこともできる. そのひとつの方法として,XMLの例に,異なる名前空間を与えると いう手段がある. これは,このガイドラインで使われている手法でもある. もうひとつの方法には,SGMLからXMLへと引き継がれた機能を使う 手法である. これは,「マーク付きセクション」と呼ばれている.
<![CDATA[<line>....</line>]]>
- « v.vi 他の構成要素
- Home | 目次
v.vii 関連づけ関連づけ¶
- XMLプロセッサは,その妥当性を検証するために,どのように スキーマを特定するのか.
- 文書の妥当性を検証する前に処理する必要のあるエンティティ 参照を含む場合,そのエンティティはどこで定義すればよいの か.
- XML文書は,様々なOS上で使われることになる. その時,それらをどのように統合すべきなのか.
- どのスタイルシートを使うべきなのかを,処理系はどのように 知ることができるのか.また,どのようにPIを解釈すべきなの か.
- 処理系は,単純なデータ型よりも複雑な,妥当性の制約を, (例えば,要素内容に)どのように科せばよいのか.
これらの問題に対する姿勢は,スキーマ言語毎に異なっている. 理由は,その方針がXMLの規格で示されていないからである. その結果として,一番の解決策は,それぞれのスキーマ言語やソフ トウェア環境毎に最適解は変わってくる. 本章の目的は,個々の処理環境からは独立して,XMLを紹介するこ とであるから,これら個別の問題は,ここにまとめて紹介してしま うことにする.
- » 文書とスキーマの関連づけ
- Home | 目次
文書とエンティティ定義の関連づけTEI: Associating entity definitions with a documentinstance¶
文字参照の節で,eacute のような名前による文字参照の書式を紹介したが,これは,XML がSGMLから継承した仕組みである. スキーマ言語は,それぞれ独自の方法でXMLプロセッサとの連携 が決められているものの,幸いに,現在あるどのスキーマ言語で も共通してサポートしているひとつの手法がある.
XML宣言(PI)に続いて,XML文書インスタンスを書く前に, 特別なDOCTYPE宣言を書くことがある. この宣言は,XMLがSGMLから継承した仕組みである. この仕組みには多くの機能が用意されているが,ここではどのス キーマ言語でもサポートしている機能についてのみ解説をする.
<!ENTITY mdash "ߞ">
<!ENTITY legalese "This document is available under a Creative CommonsShare and Enjoy Licence">
]>
文書とスキーマの関連づけTEI: Associating a document instance with its schema¶
スキーマ言語毎に,文書とスキーマを関連づける方法は異なって いる. XML文書は,スキーマにより妥当性が判定されるが,それを判定 するソフトウェアは,スキーマ言語毎に異なる処理をする. 例えば,RELAX NGには,文書とスキーマを関連づける機能はない. RELAX NGにおいて,この関連づけは,一般的なアーキテクチャの 問題における,ある特定の問題とされている(ISO DSDLの草稿よ り). 25
一方,W3CのXML Schemaと,XMLがSGMLから継承したDTDでは,文 書から直接,妥当性を判断するための情報を参照することが可能 である. W3CのXML Schemaでは,一般に,ルート要素の属性を使い,それ を実現することになる. また,XML DTDでは, 文書とエンティティ定義の関連づけ で解説されている,DOCTYPE宣言を使い,それを実現し ている.
幸いなことに,今あるXMLプロセッサには,文書とスキーマを関 連づける方法が用意されている. 従って,文書の可搬性を最大限に高めたいのであれば,処理系に 依存した情報は文書中には含めない方がよい.
- « 文書とスキーマの関連づけ
- » スタイルシートと処理の関連づけ
- Home | 目次
複数の文書類をひとつの文書にまとめるTEI: Assembling multiple resources into a single document¶
先に見たように,XML文書は,複数の異なる部分から構成される ことがあり,その際には,当該文書の妥当性が検証される前に, それらは統合される必要がある. XML DTDでは,特別なエンティティ(システムエンティティ)が定 義されている. このエンティティは, 文字参照で紹介したエンティティと同様に,別のファイルを参照する機 能を持っている. RELAX NGとW3C Schemaでは,この機能は用意されていない. この詳細は,ここでは扱わない.
これと同様の効果を持つ仕組みとして,先の作品集の例で示した ような,ある特別な要素を使い,統合すべき内容を参照すること はできる. W3Cでは,このような仕組みとして XML Inclusions (XInclude)26 という,一般的な機能を定義している. この機能をサポートするソフトウェアの数は増えてきている.
- « 複数の文書類をひとつの文書にまとめる
- Home | 目次
スタイルシートと処理の関連づけTEI: Stylesheet association and processing¶
XML文書を処理する際には,表示に関して特化したスタイルシー トを複数使うことが一般的である. 一般に,XML文書と特定のスタイルシートやスキーマ言語を関連 づける理由は,特に存在しないことから,その関係は,明示して おく必要がある. スタイルシートの処理ソフトが起動されたときに,その関連性が 作られることから,アプリケーションに特化した関係といえる.
しかし,XML文書とスタイルシートとの関連づけは,ブラウザで 表示するときの一般的な利用の形態であることから,W3Cでは, その関連づけを示す文法と手順を定義している(詳細は http://www.w3.org/TR/xml-stylesheet/ を参照). この規格は,XML文書に,デフォルトのスタイルシートへのリンク を張る手段を提供している. また,「MIME型」を使いスタイルシートを分類する方法も提供して いる. 例えば,CSSやXSLTによるスタイルシートを処理する方法を示して いる.
今ある殆どのブラウザーでは(程度の違いはあるが)CSSがサポートされている. また,いくつかのブラウザーでは,XSLTもサポートされている.
内容の検証TEI: Content validation¶
先に示したように,殆どのスキーマ言語では,属性値のデータ型を 検証する機能がある (属性リスト宣言). このような機能は,これまでに紹介した文法による制約以上に,要 素内容を実際に処理するソフトウェアにより変わってくる. 例えば,要素stanzaの内容には,要素 lineしか取れないことを確認するのは簡 単であるが,一方で,要素lineの内容に 正しい英単語が5語から500語存在することを確認することは,簡単 なことではない. また,属性と要素の処理は,異なることから,その関係を同時に制 約することは難しく,また,不可能である. 例えば,詩の状態をdraftと表現したと きに,要素editorialQueryを,子要素と して取れるようにして,そうでない場合には認めない,という制約な どである.
XML DTDでは,要素内容に関する統語的な確認を行うことは殆どない. 一方,W3C Schemaは,XML DTDよりも,この種の制約を一般化し, 強化することを目標として作られている. RELAX NGでは,データ型の検証は,属性値であれ,要素内容であれ, 外部のスキーマ言語に任せる,という哲学を採っている. 例えば,RELAX NGでは,属性値に対して,W3C Schemaのデータ型ラ イブラリを使っている(他のものも使うことが出来る). RELAX NGでは,要素も属性も,共にパタンとして扱うことが可能で あり,この両方に同じデータ型の検証をかけることが可能である. これは,他のスキーマ言語とは異なる点である. さらに,要素内容の検証では,DSDLにあるもうひとつのスキーマ言 語であるSchematronも使うことができる. Schematronは,(文法ベースというよりは)パターンマッチング言語 で,制約を定義したテンプレートに従って,文書の部分を検証する ことができる.
Shematronは,他のXMLプロセッサと同様,XPathを使い,XML文書の 部分を特定することができる. さらには,要素に加えて,宣言や条件を示す要素も検証することが 可能である.
↑ Contents « iv ガイドラインについて » vi 言語と文字集合